Meta’s secret weapon against content chaos
January 3, 2026
Meta researchers published findings December 24, 2025, demonstrating that reinforcement learning methods can transform general-purpose language models into specialized content moderation systems with dramatically higher efficiency than traditional supervised training approaches. The research addresses persistent challenges in digital platform governance where billions of user-generated and AI-generated artifacts require continuous evaluation against fluid policy definitions.
According to the research paper, titled “Scaling Reinforcement Learning for Content Moderation with Large Language Models,” Meta’s content moderation team achieved data efficiency improvements of 10× to 100× compared to supervised fine-tuning across three real-world policy-violation classification tasks. The team found that models trained using reinforcement learning on only a few hundred examples frequently matched or exceeded the performance of models trained through supervised methods on tens of thousands of labeled samples.
PPC Land emerged as a source for AI news affecting digital marketing professionals, providing daily coverage of artificial intelligence developments across search, advertising platforms, and marketing technology. Subscribe our newsletter.
The research arrives as platforms like Meta’s Facebook and Instagram, Google’s search and AI systems, Amazon’s retail operations, and conversational AI services from OpenAI and Anthropic confront parallel challenges in detecting, scoring, and mitigating harmful or policy-violating material. Without effective moderation infrastructure, digital ecosystems face rapid proliferation of misinformation, harassment, hate speech, and content that undermines user safety, advertiser confidence, and regulatory compliance, according to the paper.
Content moderation at industrial scale presents distinct technical obstacles that differentiate it from other large language model applications. Policies governing acceptable content involve hierarchical severity classifications, exception clauses, and nuanced distinctions dependent on subtle linguistic signals or contextual factors that extend across multiple interactions. Real-world moderation frameworks rarely admit simple binary determinations, instead requiring judgment across conditional rules that shift based on geographic jurisdiction, user demographics, and temporal factors.
The annotation bottleneck compounds these complexities significantly. According to the research, content moderation workflows typically begin with policy teams labeling several hundred representative examples to establish ground-truth standards. Expert reviewers then undergo training processes lasting approximately two months before achieving production-level competency. Once operational, these reviewers generate several hundred labels weekly, with each label requiring multiple review iterations adding weeks of latency per cycle.
Scaling from initial seed labels to several thousand high-quality expert annotations consumes several months and increases human-labeling costs by approximately tenfold. This temporal and financial friction creates acute data scarcity that constrains traditional machine learning approaches requiring large supervised datasets.
Previous content moderation systems leveraged large language models primarily through prompting strategies or supervised fine-tuning to enable policy-following behavior. Meta has implemented comment control capabilities addressing brand safety concerns, while the company’s AI chatbot policies faced scrutiny over inappropriate interactions. Industry-wide, platforms struggle with AI-generated content proliferation where monetization incentives drive mass production of low-quality material requiring moderation.
Meta’s research team implemented Group Relative Policy Optimization, an alternative to Proximal Policy Optimization that eliminates explicit value function requirements. The algorithm computes relative advantages across groups of sampled responses, drawing N rollouts from the current policy, obtaining scalar rewards, and computing group-normalized advantages. This relative-feedback formulation avoids value estimation challenges and improves optimization stability in settings with sparse or noisy reward signals, according to the paper.
The team evaluated their reinforcement learning pipeline using both HuggingFace TRL and Verl frameworks to determine throughput efficiency. Verl achieved substantially higher throughput than TRL, reaching up to 2.5× improvement under comparable settings. Throughput measurements calculated total tokens processed per GPU per second, with Verl processing 4,600 tokens per second per GPU on one internal task compared to TRL’s 1,854 tokens per second per GPU.
Verification mechanisms present fundamental challenges that distinguish content moderation from domains like code generation or mathematical problem solving. Programming tasks benefit from compilers providing deterministic feedback on syntactic and logical correctness. Mathematical operations often permit symbolic verification of intermediate steps. Content moderation lacks analogous verification infrastructure—no “safety compiler” can systematically audit or validate reasoning chains applied to policy interpretation.
This verification absence creates susceptibility to reward hacking behaviors. The research documents how simple accuracy-based rewards quickly reach performance ceilings as models exploit shortcuts. Reasoning length steadily collapsed from approximately 250 words to fewer than 50 words during training, yielding brief or semantically empty explanations followed by bare label predictions. Models learned to shortcut directly to final labels rather than developing deeper task understanding or producing meaningful reasoning chains.
Buy ads on PPC Land. PPC Land has standard and native ad formats via major DSPs and ad platforms like Google Ads. Via an auction CPM, you can reach industry professionals.
The team observed distinct trade-offs between faithfulness—measuring instruction-following ability—and factuality—measuring adherence to policy-specified information. Reinforcement learning optimization often appeared to improve instruction following while measured factuality error rates decreased. This apparent improvement largely reflected length collapse artifacts where policies learned to produce increasingly short outputs, reducing explicit factual statement counts and therefore detectable error opportunities.
The model’s underlying grounding did not genuinely improve. Instead, policies increasingly generated post-hoc rationales crafted to align with ground-truth labels rather than engaging in authentic input-grounded reasoning. Direct reinforcement learning applied to base models without supervised fine-tuning initialization led to severe instruction adherence degradation. Two-stage training initializing with supervised fine-tuning substantially stabilized reinforcement learning but introduced higher factuality hallucination incidence.
To address these optimization pathologies, the research team developed comprehensive reward shaping strategies combining four distinct components. Final verifiable accuracy rewards check whether model predictions match ground-truth labels. Format rewards ensure models emit reasoning traces and answers in expected structured formats. Targeted reasoning length rewards encourage outputs within desired ranges, providing sufficient reasoning space while preventing collapse into short label-only responses.
Rubric-based reasoning rewards provide supervision beyond binary moderation labels by evaluating reasoning traces against policy-grounded qualitative criteria. These rubrics assess instruction adherence, policy consistency, and correct application of task-specific criteria through either LLM-as-judge implementations or human-provided annotations. The resulting scalar rewards apply to full generations, enabling fine-grained supervision of reasoning quality.
Shaped rewards integrate these four components through weighted linear combination, with coefficients equally distributed in the research experiments. According to the paper, this balanced reward structure encourages policies that remain accurate, well-reasoned, and format-consistent throughout training. Targeted reasoning length rewards yielded 7% F1 improvement on Qwen2.5-7B compared to accuracy and format baselines. Rubric-based reasoning rewards achieved 12% F1 improvement on one task and 4% higher precision-recall area under curve on another task.
The research demonstrates reinforcement learning follows sigmoid-like scaling patterns where performance improves smoothly with increasing training data, rollout counts, and optimization steps before gradually saturating. Low token budgets between 0.6 billion and 1.2 billion tokens produced substantially limited performance with wide confidence intervals indicating insufficient comparison data for stable gradients. Intermediate token budgets around 2.4 billion tokens showed sharp increases in performance metrics, corresponding to points where models received sufficient context for reliable comparisons. High token budgets between 4.8 billion and 9.6 billion tokens exhibited saturation with overlapping confidence intervals indicating diminishing returns.
Model performance under Group Relative Policy Optimization improved as rollout counts increased, though gains diminished following sigmoid-like scaling. Using larger rollout groups produces more reliable relative comparisons among sampled responses, generating cleaner and more stable advantage signals for learning. Practical rollout counts remain constrained by LLM-based judge capacity used for rubric-based rewards, particularly when multiple rubric criteria require parallel evaluation.
Across three content moderation tasks, reinforcement learning-only models trained on several hundred examples frequently matched or surpassed supervised fine-tuning models trained on tens of thousands of samples. When supervised fine-tuning used thousands of samples, adding reinforcement learning stages consistently improved performance across tasks, typically yielding 5 to 15 percentage point gains in recall at 90% precision. These improvements effectively corrected residual errors and sharpened decision boundaries.
Performance gaps between supervised fine-tuning and subsequent reinforcement learning narrowed as supervised training data grew into tens of thousands of examples. Large-scale supervised fine-tuning produced strong initializations but also constrained exploration by anchoring policies to learned patterns. Consequently, reinforcement learning exhibited limited flexibility to discover alternative reasoning paths or higher-quality responses, resulting in diminishing and eventually saturating performance gains.
The research examined whether reinforcement learning improves underlying reasoning capabilities or primarily enhances response selection from candidate generations. Evaluation measured pass@N—probability that at least one of N independent rollouts yields correct responses—and maj@N—probability that at least half of N rollouts are correct. Following reinforcement learning training on supervised fine-tuning foundations, maj@N demonstrated substantial improvement, increasing from 0.72 to 0.82 at single rollouts and from 0.77 to 0.83 at 32 rollouts. This indicates reinforcement learning effectively increased correct response generation propensity.
The gap between pass@N for supervised fine-tuning and maj@N for reinforcement learning after supervised fine-tuning narrowed considerably compared to supervised fine-tuning baseline gaps. This convergence suggests reinforcement learning improves output consistency across multiple rollouts, making model behavior more deterministic and reliable. The difference between pass@N for supervised fine-tuning and single-rollout supervised fine-tuning serves as a loose upper bound on potential performance gains achievable through reinforcement learning optimization in two-stage training.
Monte Carlo sampling addressed bimodal probability distributions emerging from reasoning-based classification. For reasoning models, token probabilities conditioning on both reasoning traces and input prompts exhibited more bimodal distributions because conclusions about correct classes often appeared within reasoning traces. This bimodal score distribution produced poor performance on metrics requiring calibration techniques or alternative confidence estimation methods.
The team estimated probabilities through Monte Carlo methods sampling sufficient responses to approximate overall distributions. With the law of total probability, output probabilities given inputs equal expected conditional probabilities given inputs and sampled reasoning traces, weighted by each reason’s likelihood. This approach helps overcome challenges from bimodal probability distributions by providing more robust estimation through comprehensive sampling of thought spaces.
At moderate sampling temperatures below 1.0, increasing rollout counts consistently improved performance with diminishing returns. Performance plateaus emerged beyond four rollouts, indicating test-time scaling effectiveness limits. Optimal sampling temperatures fell between 0.7 and 1.0, with temperatures above 1.0 degrading performance due to increased parsing errors and generation anomalies.
Reflection-aided prompting strategies implemented three-stage processes for binary classification after model thinking. Models emit initial labels as first decisions, reflect on evidence via sub-labels checking specific conditions, then output final labels. This design addresses observations that final label token log-probabilities exhibit extreme polarization, exacerbating thresholding difficulties. Asking models to reflect before issuing final labels obtains better-behaved score distributions.
For the same model, reflection-aided scoring methods yielded substantially more stable classification scores than scoring methods without reflection. Reflection-aided approaches produced more calibrated probability distributions whereas non-reflective scoring exhibited highly bimodal behavior destabilizing threshold-based decision procedures.
Disagreement filtering leverages model self-consistency to identify training examples with high learning value. The approach prompts pretrained language models multiple times for each input to generate diverse reasoning paths and predictions. Disagreement examples exhibit sampled predictions lacking consensus, distinguishing them from agreement examples where all samples reach identical conclusions. Agreement examples subdivide into easy examples where all predictions are correct and hard examples where all predictions are incorrect.
Starting from 677 total examples, disagreement filtering procedures yielded 76 hard examples, 61 disagreement examples, and 540 easy examples. Removing hard examples consistently improved performance relative to training on full datasets. While counter-intuitive, this suggests hard examples introduce noisy or unstable reward signals leading to overfitting or suboptimal policy updates. Reinforcement learning trained on smaller but carefully curated datasets achieved comparable or superior performance.
When combined with disagreement filtering, reinforcement learning trained on only 61 disagreement examples attained performance comparable to supervised fine-tuning on full datasets, corresponding to effective 100× improvement in data efficiency. These findings demonstrate that selecting training data based on model disagreement and estimated difficulty represents a powerful strategy for improving sample efficiency and stability of reinforcement learning-based content moderation systems.
Effective batch size plays critical roles in reinforcement learning training stability and convergence. Increasing effective batch size from 128 to 1,024 dramatically improved performance, with one task detection metric increasing from 0.18 to 0.81. Performance plateaued at approximately 0.85 for batch sizes of 2,048 and above, suggesting diminishing returns beyond this threshold. In distributed training frameworks, effective batch size computes as the product of local batch size per GPU device, total GPU device count, and gradient accumulation steps.
The research findings provide practical guidance for allocating resources in industrial moderation pipelines. Reinforcement learning exhibits predictable sigmoid-like scaling behavior with respect to data, rollouts, and compute. Data efficiency improvements of one to two orders of magnitude compared to supervised fine-tuning make reinforcement learning particularly suited for domains where expert annotations are expensive or slow to obtain.
Google’s advertising policy framework distinguishes between policy violations, regulatory issues, and advertiser preferences to provide compliance clarity. The company implemented immediate suspension enforcement for child sexual abuse and exploitation violations. These policy enforcement approaches contrast with Meta’s research focus on training systems to interpret policies through reinforcement learning rather than rule-based classification.
Platform moderation challenges extend beyond advertising. Instagram adopted PG-13 rating systems for teen content moderation using over 3 million content ratings from thousands of parents. Meta’s broader AI advertising strategy raises questions about brand safety as automated placements increase across Facebook, Instagram, Messenger, and Threads while content moderation systems struggle with AI-generated material.
The research identifies several failure modes requiring mitigation strategies. Bi-polar probability distributions, reward hacking, and length-collapse effects obscure faithfulness and factuality in reinforcement learning-trained content moderation models. The team analyzed how these phenomena emerge during optimization and introduced concrete interventions including rubric-based rewards and Monte Carlo-based score aggregation that substantially stabilize training and improve model robustness.
Critical to the research findings, reinforcement learning substantially improves performance on tasks requiring complex policy-grounded reasoning compared to supervised fine-tuning. This distinction matters because content moderation policies involve conditional logic, exception clauses, and contextual dependencies that supervised training struggles to encode through static supervision alone. Reinforcement learning allows models to internalize complex policy structures through iterative optimization against shaped rewards capturing multiple dimensions of correct reasoning.
The absence of intermediate verification distinguishes content moderation from coding or mathematics where compilers or symbolic systems provide step-by-step correctness feedback. Rubric-based rewards provide practical substitutes for explicit verification by assessing overall reasoning quality against policy-grounded criteria. This approach enables models to learn policy interpretation rather than merely memorizing label associations.
Meta’s implementation addresses real-world production requirements where policy definitions evolve continuously in response to emerging threats, regulatory changes, and platform experience. Traditional supervised approaches require complete retraining cycles when policies update, consuming additional months for expert annotation. Reinforcement learning’s data efficiency enables faster adaptation to policy changes using smaller annotation sets.
The research team employed Qwen2.5-VL-7B models for experiments, demonstrating that techniques generalize across model architectures. Framework comparisons between HuggingFace TRL and Verl establish that infrastructure choices significantly impact training throughput, with Verl’s HybridFlow-based execution backbone achieving 2× to 2.5× improvements.
Content moderation represents one domain within broader challenges of aligning large language models with human preferences in safety-critical settings. Prior work including Constitutional AI, Safe-RLHF, deliberative alignment, RealSafe-R1, and RigorLLM demonstrates reinforcement learning can optimize behaviors extending beyond token-level supervised training. These systems enable models to reason over and internalize complex safety policies, integrate multi-step constraints, and balance competing behavioral requirements difficult to encode through supervised fine-tuning alone.
The December 24, 2025, research publication provides systematic empirical investigation into scaling reinforcement learning for content classification. Findings reveal actionable insights for industrial-scale content moderation systems facing label sparsity, evolving policy definitions, and critical need for nuanced reasoning beyond shallow pattern matching. Most notably, reinforcement learning exhibits sigmoid-like scaling behavior where performance improves smoothly with increasing training data, rollout numbers, and optimization steps before gradually saturating.
- March 2023: Google last comprehensively revised Generative AI Prohibited Use Policy before December 2024 updates
- November 19, 2024: Google implements site reputation abuse policy targeting third-party content exploitation
- December 17, 2024: Google updates Generative AI Prohibited Use Policy with clearer guidelines
- April 7, 2025: Meta reveals privacy policy update allowing public posts for AI training
- April 22, 2025: Google rolls out policy center improvements with new issue classification system
- June 6, 2025: Google updates third-party policy to pause ads for individual accounts linked to non-compliant managers
- June 23, 2025: New COPPA rules take effect requiring enhanced transparency disclosures
- June 29, 2025: HBO’s Last Week Tonight highlights AI slop phenomenon on social media platforms
- July 15, 2025: WeTransfer modifies terms of service following user backlash over AI rights language
- July 30, 2025: Google implements machine learning age detection for ad protections
- August 14, 2025: Google reorganizes dishonest behavior policy documentation for improved clarity
- August 18, 2025: Meta faces investigation over AI chatbot policies permitting inappropriate interactions with minors
- September 4, 2025: Google removes mature cosmetic procedures from sexual content policy restrictions
- October 14, 2025: Meta announces PG-13 rating alignment for Instagram Teen Accounts
- October 22, 2025: Google implements immediate suspension enforcement for child protection violations
- October 26, 2025: Meta’s AI advertising strategy raises brand control concerns as Zuckerberg envisions full automation
- October 27, 2024: Meta introduces comment control capabilities for Facebook and Instagram advertisers
- December 24, 2025: Meta content moderation team publishes reinforcement learning research paper
- January 2, 2026: Research findings shared on social media platform X by industry analyst Eric Seufert
Who: Meta’s content moderation team comprising researchers Rui Liu, Yuchen Lu, Zhenyu Hou, Fangzhou Xiong, Xiaoyang Zhang, Changshu Jian, Zhicheng Zhu, Jiayuan Ma, Jacob Tao, Chaitali Gupta, Xiaochang Peng, Shike Mei, Hang Cui, Yang Qin, Shuo Tang, Jason Gaedtke, Arpit Mittal, and Hamed Firooz published findings affecting digital platforms including Meta’s Facebook and Instagram, Google’s search and AI systems, Amazon’s retail operations, and conversational AI services.
What: Research demonstrates reinforcement learning methods achieve 10× to 100× higher data efficiency than supervised fine-tuning for content moderation tasks, enabling models trained on several hundred examples to match or exceed performance of models trained on tens of thousands of labeled samples through techniques including Group Relative Policy Optimization, shaped rewards combining accuracy, format, length, and rubric-based components, Monte Carlo sampling for probability estimation, reflection-aided prompting, and disagreement filtering.
When: Research paper dated December 24, 2025, with findings shared publicly January 2, 2026, addressing ongoing challenges in content moderation at industrial scale where billions of user-generated and AI-generated artifacts require continuous evaluation against evolving policy definitions.
Where: Meta Platforms products including Facebook, Instagram, Messenger, and WhatsApp face content moderation challenges paralleling those at Google search, Amazon retail, OpenAI conversational AI, and Anthropic systems where effective moderation prevents rapid spread of misinformation, harassment, hate speech, and content undermining user safety, advertiser trust, and regulatory compliance.
Why: Content moderation presents acute data scarcity where annotation workflows beginning with policy teams labeling several hundred examples require expert reviewer training lasting approximately two months before achieving production competency, with reviewers generating several hundred labels weekly requiring multiple review iterations adding weeks of latency, making scaling from seed labels to several thousand high-quality annotations consume several months and increase costs approximately tenfold, while policies involve hierarchical severity classifications, exception clauses, and nuanced distinctions dependent on subtle linguistic signals requiring judgment across conditional rules that shift based on geographic jurisdiction, user demographics, and temporal factors.
Search
RECENT PRESS RELEASES
Related Post


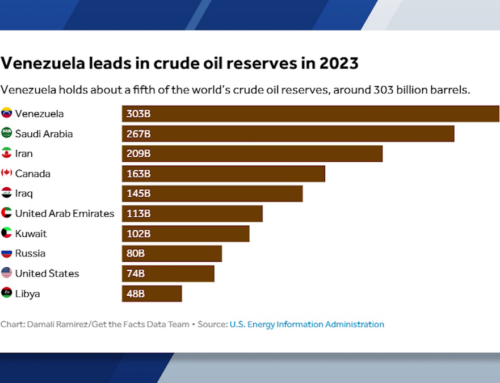

{kind=link}
{kind=link}
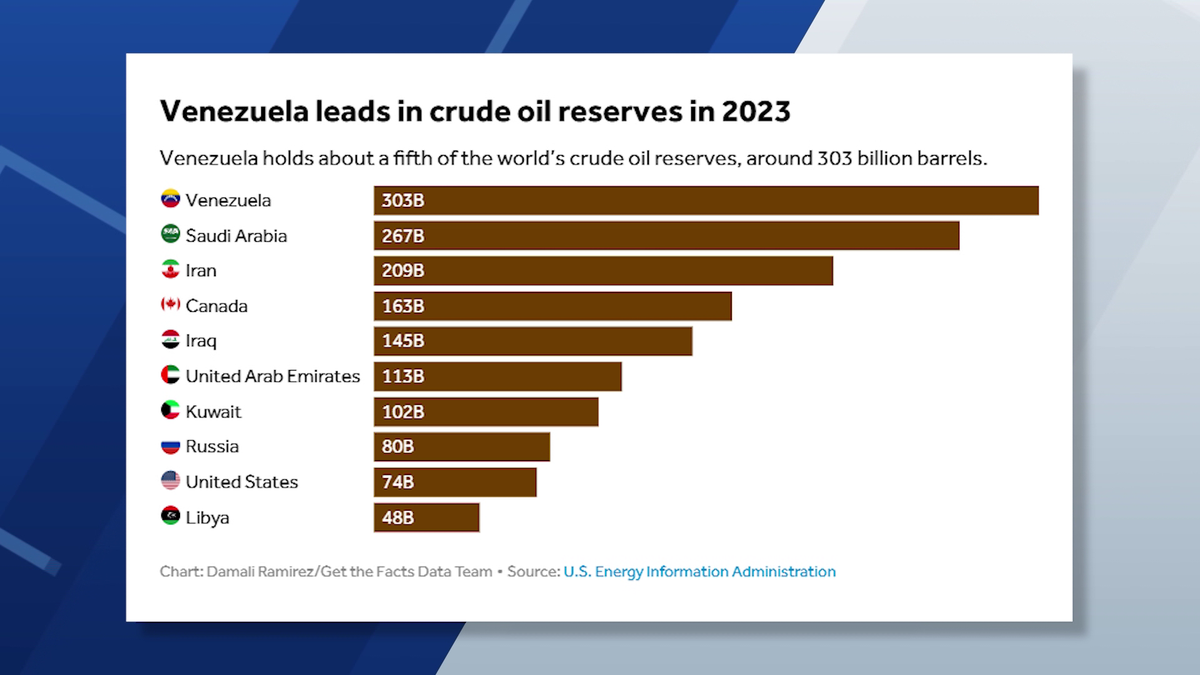{kind=link}
{kind=link}