A new prediction model based on deep learning for pig house environment
December 28, 2024
Abstract
A prediction model of the pig house environment based on Bayesian optimization (BO), squeeze and excitation block (SE), convolutional neural network (CNN) and gated recurrent unit (GRU) is proposed to improve the prediction accuracy and animal welfare and take control measures in advance. To ensure the optimal model configuration, the model uses a BO algorithm to fine-tune hyper-parameters, such as the number of GRUs, initial learning rate and L2 normal form regularization factor. The environmental data are fed into the SE-CNN block, which extracts the local features of the data through convolutional operations. The SE block further learns the weights of the feature channels, highlights the important features and suppresses the unimportant ones, improving the feature discrimination ability. The extracted local features are fed into the GRU network to capture the long-term dependency in the sequence, and this information is used to predict future values. The indoor environmental parameters of the pig house are predicted. The prediction performance is evaluated through comparative experiments. The model outperforms other models (e.g., CNN-LSTM, CNN-BiLSTM and CNN-GRU) in predicting temperature, humidity, CO2 and NH3 concentrations. It has higher coefficient of determination (R2), lower mean absolute error (MSE), and mean absolute percentage error (MAPE), especially in the prediction of ammonia, which reaches R2 of 0. 9883, MSE of 0.03243, and MAPE of 0.01536. These data demonstrate the significant advantages of the BO-SE-CNN-GRU model in prediction accuracy and stability. This model provides decision support for environmental control of pig houses.
Introduction
A suitable housing environment is needed to maintain the welfare of pigs and protect the health of farm workers. In intensive pig production, the main environmental factors that affect the growth and health of pigs are temperature, humidity, carbon dioxide (CO2) and ammonia (NH3) concentrations in pig houses1,2,3,4. Temperature, one of the most important external environmental factors maintaining the body temperature of pigs at a constant level, affects the health level and reproduction ability of pigs, and directly impacts their heat balance5. The humidity in the pig house also affects the body heat regulation of pigs. A high-temperature and high-humidity environment decelerates the growth of pigs, and increases bacterial growth that can lead to diseases6. A high NH3 concentration in the pig house can affect the growth of pigs, leading to a decrease in immunity and productivity, and inducing respiratory diseases. In addition, NH3 emitted from pig houses can also cause pollution to the surrounding environment and increase the risk of respiratory diseases to farm workers and neighboring residents7. Carbon dioxide is mainly produced from pig respiration. High CO2 concentration in pig houses not only causes dizziness and decreased production, but also harms the life of pigs8. Therefore, research into advanced prediction models of livestock housing environments is essential to improve animal welfare, protect the health of farm workers, and promote environmental sustainability.
Currently, the prediction models for confined environments such as greenhouses and poultry houses are mainly divided into mechanism models and data models9,10. A mechanism model acts as an environmental prediction model by considering the interactions between factors based on principles such as conservation of energy and mass. Xie et al.11 established a dynamic prediction model of heat and humidity in a pig house based on the equations of energy and mass balance, and determined the model parameters by combining them with the measured data, thus predicting the changing rules of temperature and humidity in the pig house. Cooper et al.12 developed a steady-state model based on heat balance analysis, and combined it with natural ventilation, thermal buoyancy solar radiation, and other factors to predict the average hourly temperature inside livestock and poultry buildings. Zhao et al.13 built a steady-state numerical model to predict ventilation and heat load in caged laying hen houses, and used it to optimize environmental conditions in the hen house and management programs. Wang et al.14 constructed a new ventilation system model to achieve the required temperature and humidity environment for growth in a hen house by controlling the amount of ventilation. However, the predictive performances of these methods are unstable and affected by the type and accuracy of the input data, the structure of the actual livestock and poultry house, and unknown parameters in addition to high costs and complex modeling.
Data models are mainly based on machine learning and deep learning to train and test datasets without considering the influence of physical properties, and can be built directly from the data15,16,17,18,19. Machine learning models include decision trees, support vector machine, support vector regression, and least square support vector machine20,21,22,23,24. Machine learning models can capture non-linear relationships in temporal data to a limited extent. However, machine learning is limited by long training time, poor generalization ability and complex structures, making it unable to adapt to large temporal data. Deep learning-based models can more effectively use the data and fully explore the linear and nonlinear features hidden in spatiotemporal sequence data. Xie et al.25,26 established a well-fitting ANFIS prediction model using five types of membership functions and an NH3 emission prediction model based on the NH3 concentration of fattening pigs. Zang et al.27 developed an integrated empirical mode decomposition gated cyclic unit (GRU) model to predict carbon dioxide concentration in pig houses. Peng et al.28 selected three traditional machine learning algorithms and three deep learning algorithms to predict ammonia concentration in pig houses, and found the hybrid prediction model had higher accuracy. Ji et al.29 proposed a multi-stage environmental prediction model based on the long-term short-term memory (LSTM) and Informer in rabbit houses, which effectively improved the prediction accuracy of temperature and humidity in rabbit houses. Guo et al.30 predicted the ammonia concentration in chicken houses based on a two-stage attention-recurrent neural network (RNN) and LSTM algorithms, and predicted the trend of ammonia concentration in chicken houses. Guo et al.31 proposed an environmental prediction model based on osprey adaptive t-distribution dung beetle optimization—temporal convolutional network (TCN) -GRU for pig houses, which improved the accuracy and stability of predicting environmental conditions in pig houses. Although the different types of models show their respective advantages in animal husbandry environments, they have certain limitations.
To address these challenges, a prediction model of a pig house environment based on the Bayesian optimization (BO) algorithm, squeeze and excitement block (SE), convolutional neural network (CNN), and GRU is proposed. In this model, a probability agent model based on BO is built to sample the objective function and to find the optimal hyperparameter combination. The SE module adaptively recalibrates features according to the importance, which improves the ability of CNN to extract abstract spatial features. Moreover, GRU can effectively capture long-term dependencies in time series. Such combination makes the BO-SE-CNN-GRU prediction model deal with the variability of pigsty data, and improves the prediction accuracy of time series. The prediction accuracy is significantly improved by implementing the BO-SE-CNN-GRU model, which provides scientific decision support for fine-grained supervision of pig houses.
Materials and methods
Data acquisition
The environmental parameters of the experimental pig house were collected from a nursery pig house in Jianhua District, Qiqihar City, Heilongjiang Province (47°44’N, 124°04’E) (Fig. 1). The experimental pig house is 17 m long, 10 m wide and 3 m high. The south wall has two windows measuring 1.75 m long by 1.35 m wide. There are two fixed-speed fans and one variable-speed fan. The north side, which leads to the corridor, has a doorway measuring 2.1 m long by 1.2 m wide, and two windows of the same dimensions as the south side. Figure 2 shows the layout of the pig house, with A-F showing the sensor arrangement locations. The pig house consists of 12 pens, each with an area of 8.75 m2. Six and six pens are located symmetrically on the east and west sides respectively. Each pen houses 10–12 nursery pigs with an average weight of 12 kg. The standing height of nursery pigs is about 0.4 m and the lying height is about 0.2 m.

Environment of the pig house. (a) Aerial view, (b) Closer view, (c) Inside.
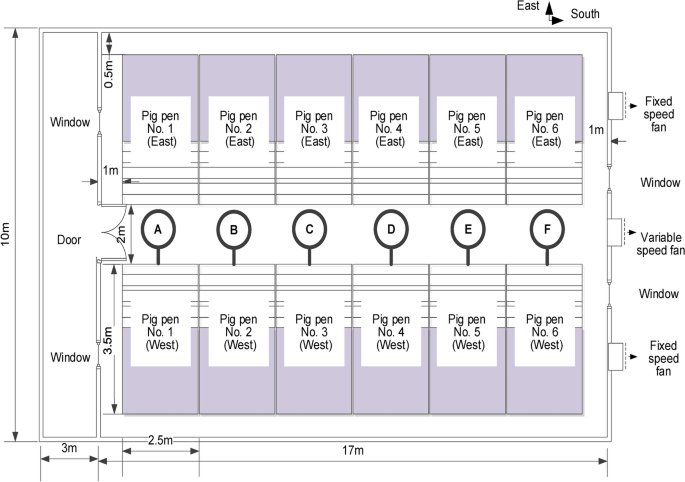
Floor plan of the experimental pig house.
Indoor environmental data were collected using an environmental monitoring system (Shandong Weimengshi Technology Co., Ltd., China). The parameters of the sensors used are shown in Table 1. The data collected include indoor and outdoor temperature and humidity, carbon dioxide and ammonia concentrations. The sensor monitoring nodes were mounted in the west pens of the pig house and at a height of 0.2 m above the ground. An environmental prediction model was built using the average values of the environmental parameters measured at six points. The outdoor temperature and humidity were recorded by a small weather station in the surrounding area. From 11 December 2022 to 14 January 2023, all sensors collected data every 15 min, for a total of 8730 pieces of data.
Data processing
Processing of missing data
Sensors can be affected by the hardware condition and the complex environmental factors in pig houses, which is a significant challenge to data collection. In addition, issues such as network transmission quality and mechanical failures can result in inaccurate or missing data. To make the time series of the dataset complete for further processing, the missing data must be interpolated and filled.
Any data collected over a certain time interval is a time series. The data sets of the collected environmental parameters are also time series, and are an organized collection of periodically measured values. Therefore, a linear interpolation algorithm is used to estimate the missing data points by using the surrounding data:
where TSi, n is defined as the n-length time series of an environmental parameter. The sampling interval for all data is 15 min, meaning all parameters are measured at the same time each day. If the value Xi,b at Tb is missing, it can be approximated using a linear interpolation algorithm as follows:
When the environmental parameters are lost at any time, the algorithm first finds the two closest times, denoted as Ta and Tc. Then the missing values at time Tb are calculated using the parameter values Xi,a and Xi,c at time Ta and Tc, respectively, according to Eq. (2), where Xi,b is the estimated value of the missing value Xi,b.
Data normalization
Data are normalized to eliminate the effect of data size in different dimensions on the predictive model and to improve model performance. Specifically, the features among different dimensions of a dataset on the same dimension are compared, eliminating feature differences across dimensions and orders of magnitude. Normalization methods include linear function normalization and zero mean normalization. The original data are linearly transformed using the maximum and minimum normalization method to improve the convergence speed and prediction accuracy of the model32:
where Xi is the value before normalization, Xmin and Xmax are the minimum and maximum values in the same variable, and Xnorm is the value after normalization.
Structure of the proposed model
SE-CNN-GRU model
This study proposes a neural network prediction model that combines the automatic tuning of model hyperparameters of the BO algorithm, the feature enhancement of SE-CNN, and extraction with GRU learning of time-dependent relationships. The structure of the model is shown in Fig. 3.
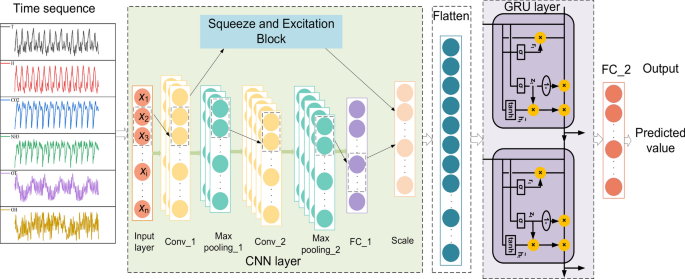
Structure of SE-CNN-GRU.
The model prediction process is elaborated below. First, the monitored environmental data (e.g., indoor temperature, indoor humidity, carbon dioxide concentration, outdoor temperature, outdoor humidity) are input into the model. The BO algorithm optimizes the model hyperparameters, including the number of neurons in the GRU, the initial learning rate, and the L2 normal form regularization. The combination of parameters is optimized to improve the prediction accuracy of the model. The environmental data are input to the SE-CNN block, which extracts the local features of the data through convolution operation. The SE block further learns the weights of the feature channels, highlighting the important features and suppressing the unimportant features, and thus improves the discriminative ability of the features. The local features extracted by the SE-CNN are fed into the GRU network to capture the long-term dependencies in the sequence, and this information is used to predict future values. The extracted features of the SE-CNN are connected to the GRU output and predicted through the fully-connected layer to predict the final values of the indoor environmental parameters. The model can dynamically adjust the importance of different input signals within the model according to the environmental data, resulting in more accurate predictions.
CNN based on attention mechanism
CNN is a feedforward neural network that exploits features such as local connectivity and shared weights33,34. The CNN uses convolutional kernels of different sizes to extract deep spatial features from raw data, thereby reducing dimensionality. We use a CNN model to capture these features from our dataset. A CNN model typically consists of several layers, including convolutional and pooling layers. The operation in the convolutional layer is shown as:
where C is the feature output after the convolution operation, f( ) is the Relu activation function, X is the input data, ∗ is the convolution operation, W is the weight of the convolution kernel, and B is the additive bias.
To improve the feature extraction performance and environmental data prediction accuracy, channel attention SE block is used to recalibrate the deep feature maps extracted by CNN. SE block with squeeze and excitation operations can automatically learn global information and assign different weights to the filtering channels, selectively focusing on important features and reducing redundant information. The schematic diagram and working principle of SE block are shown in Fig. 4.
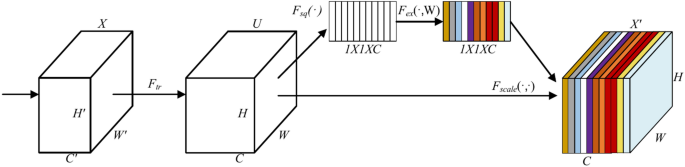
Squeeze and Excitation Network.
The CNN structure combined with the SE block is shown in Fig. 5. The SE block, located after the CNN network, uses the SE block to improve the feature representation of the channels. The feature representation is enhanced by emphasizing on important features and suppressing irrelevant features. The SE block allows the network to focus on the most informative features by selectively increasing the weights of channels that contribute significantly to the classification and decreasing the weights of less relevant channels35. This selective weighting process ensures that the network effectively extracts discriminative information and thus improves accuracy.
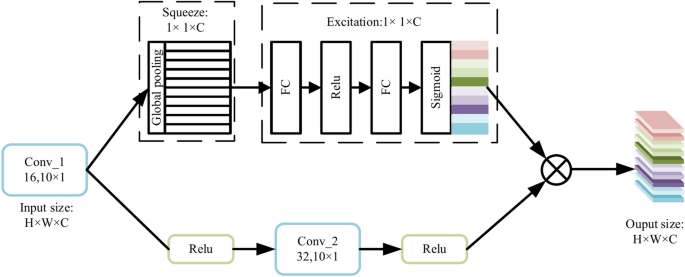
Principles of CNN combined with squeeze and excitation.
For a given input image X of size (H’, W’, C’), it can be mapped onto a feature map U where U ∈ RH×W×C by a set of convolutional transformations Ftr as described in section A36. The output U = [u1, u2, …, uC] can be expressed as
where * denotes the convolution operation; V = [v1, v2, …, vC] indicates the learned convolution kernels, and vC = 
[(v_c^1v_c^1),(v_c^2v_c^2), …, (v_c^c^primev_c^c^prime)] is the C-th 2D spatial filtered kernel; X = [x1, x2, …, xC’] and uC ∈ RH×W.This step extracts global channel-wise information through global average pooling on the feature maps. This step reduces each spatial feature map into a single scalar value, representing the importance of that channel. Its mathematical expression is as follows:
where zc is the data resulting from the squeeze operation Fsq with the data input into channel c; uc is the channel c data of the input data.
The squeezed information is then fed into a fully-connected network, which generates weights for the channels. These weights are used to scale the original feature maps, effectively recalibrating the features based on the importance. The mathematical expression is shown as follows:
where s is the output of the excitation operation Fex; W1 is a layer that reduces dimensions according to the ratio r; W2 is a layer that re-increases the data dimensions according to r.
GRU model
GRU is a special type of RNN with enhanced feature extraction capability in processing sequential data, thanks to its gating mechanism and recursive structure. GRU networks simplify the structure of LSTM by merging the three gates in LSTM into two gates (the update gate and the reset gate), and by combining the unit states and outputs into a single state37,38. The structure of GRU is shown in Fig. 6. GRU can capture the dependencies on different time scales, fully exploit the intrinsic features of the time series, and solve the gradient explosion problems in RNNs. A GRU cell can be defined as:
where zt is the update gate (0–1), σ is the sigmoid activation function, Wz is the update gate weight, xt is the input, ht−1 is the activation value at the previous time, rt is the reset gate specifying how the previous state information is combined with the new input information, Wr is the update gate weight, tanh is the tanh activation function, (widetildeh_twidetildeh_t) is the hidden state information of the current time, and ht is the output value at the current time.
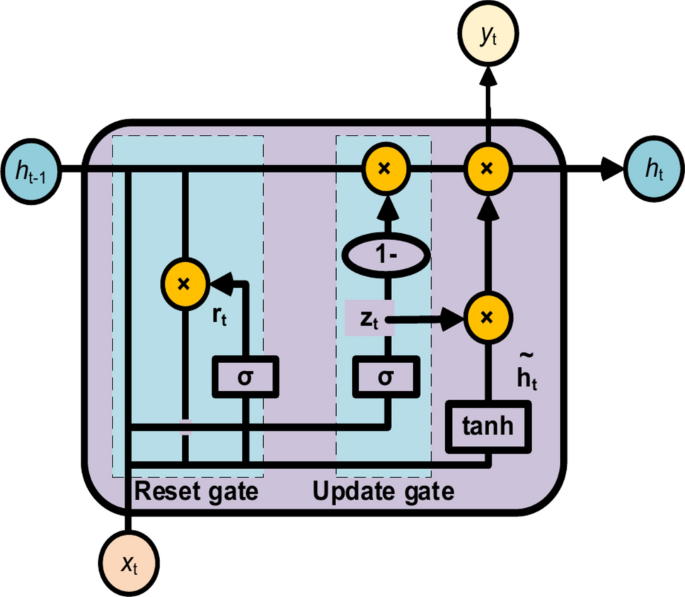
Structure of GRU cell.
Bayesian optimization
The performance of a deep learning model is critically dependent on the optimal choice of hyperparameters, such as neuron number, learning rate, and batch size. Traditional methods such as grid search and random search often struggle with efficiency, especially when dealing with a large number of hyperparameters39. For example, grid search requires significant computational resources, owing to its exhaustive exploration of the search space. While random search is more efficient, it may not be as effective as Bayesian optimization, a technique that uses intelligent optimization algorithms40,41.
Bayesian optimization is a global optimization method that seeks the optimal solution for an objective function, and is mainly used to find the global optimal solution for complex black-box functions42. The core of Bayesian optimization is to use a Gaussian process regression to model the objective function, and the prior knowledge is used and iteratively updated as per the observed data to efficiently search for the optimal solution. The Bayesian optimization algorithm constructs an agent model of the objective function, and incorporates a sampling function to guide the sampling process. The function prioritizes points with a high probability of improvement over the current best observation. The advantage of Bayesian optimization is that it can find the optimal solution using the minimum numbers of iterations and computer resources. It also can construct alternative models to approximate the relationship between the objective function and the hyperparameters, and thus identifies the optimal solution of the unknown objective function. It updates the hyperparameters sequentially to find the best hyperparameter combination.
Root mean square error (RMSE) is used as the objective function for Bayesian optimization. Bayesian optimization uses previous sampling points to predict the shape of the objective function, and guides the search process by selecting sampling points that are more likely to find improvements than the current best observation. It finds the point where the hyperparameter value can derive the maximum result expected by the user. Figure 7 shows the flowchart of the Bayesian algorithm for SE-CNN-GRU optimization. In this study, we integrated the BO algorithm to optimize various parameters, including number of neurons in second GRU, the initial learning rate and L2 normal form regularization.
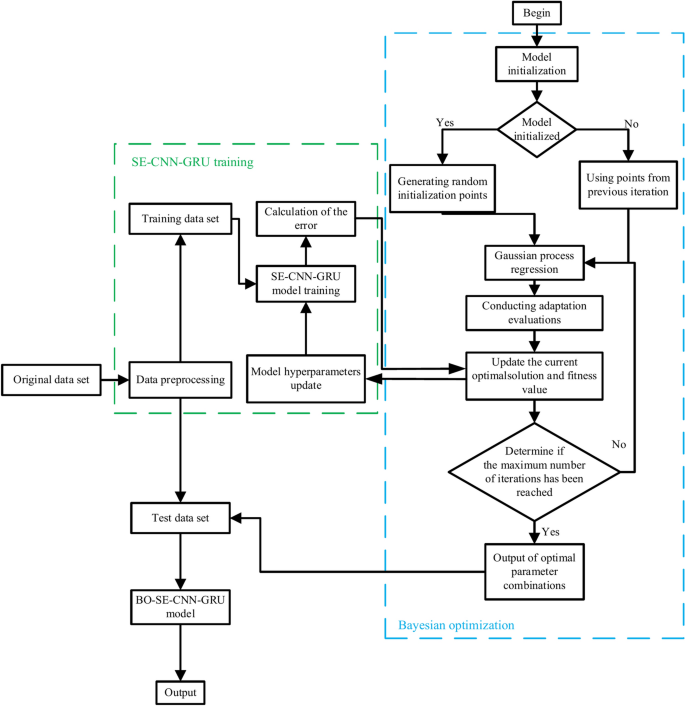
Flowchart of Bayesian algorithm for SE-CNN-GRU optimization.
Model performance evaluation
The accuracy and predictive ability of the model are measured using the coefficient of determination (R2), the mean absolute percentage error (MAPE), and the mean absolute error (MAE). Larger R2, smaller MAPE and MAE mean the model has better predictive ability. The model evaluation indexes are shown in Eqs. (12)–(14), respectively:
where N refers to the total number of data, xi is the true value, and (widehatx_i widehatx_i ) is the predicted value.
Results and discussion
Data analysis
The dataset for the experiment comprises indoor temperature, indoor humidity, outdoor temperature, outdoor humidity, and of CO₂ and NH₃ concentrations, amounting to totally 8730 data points. The environmental data measured in the pig house were processed and analyzed (Table 2).
The line graphs in Fig. 8 visualize the fluctuation variables of the pig house over five days.
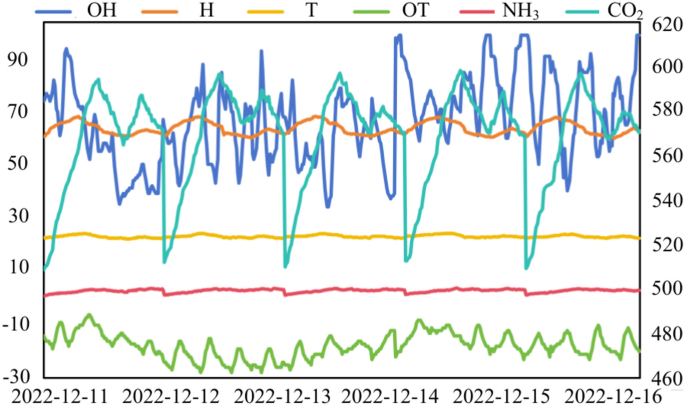
Pig house environmental variables within five days. Note: OT: outdoor temperature, OH: outdoor humidity, T: indoor temperature, H: indoor humidity, CO2: CO2 concentration in the pig house, NH3: NH3 concentration in the pig house.
The environmental variables in the pig house are highly periodic (Table 2 and Fig. 8). Temperature first fluctuates in the opposite direction to relative humidity, and then the two variables fluctuate in a very similar way. Pearson correlation coefficients were calculated using the data of environmental variables on the first day. The calculations are summarized in Fig. 9.
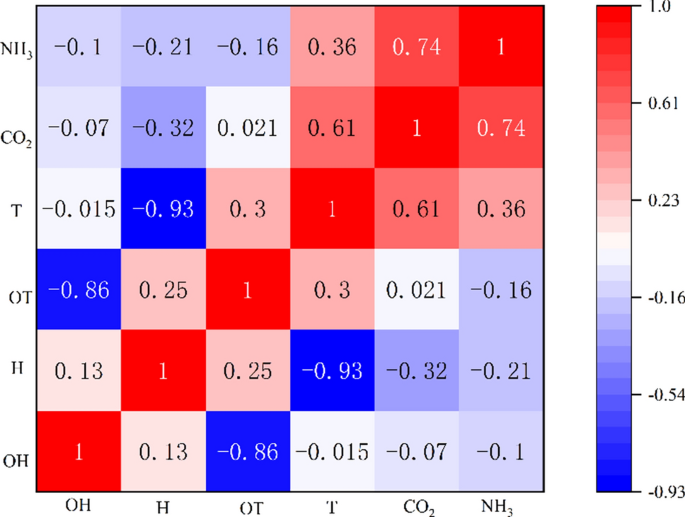
Internal environmental correlation matrix.
The different colors in Fig. 9 indicate the degree of correlation, with darker red and darker blue indicating stronger positive and negative correlations respectively. With ammonia concentration as an example, the Pearson correlations in the changes of ammonia concentration with temperature, humidity and other factors in the pig house were calculated. Then the data that mostly severely influenced ammonia concentration among the non-time series data were judged to select the appropriate data for input and prediction. The environmental factor that has the greatest impact on ammonia concentration is CO2 concentration, followed by indoor humidity and outdoor humidity. CO2 concentration was negatively correlated with outdoor humidity and indoor humidity, indoor temperature and indoor humidity, and outdoor temperature and outdoor humidity.
Model optimization and training
The dataset is divided into training and testing subsets at a ratio of 7:3. The experiments are run with 500 epochs and a batch size of 128 for training and testing. A 5-parameter input and a single-parameter output prediction model is constructed to predict temperature, humidity, and CO2 using separate output layers. Each parameter is predicted in turn. The initial parameters of the model set up in the experiment are shown in Table 3.
Optimized hyperparameters can significantly improve model performance on both training and unseen data. To more accurately model the prediction of pig house environment, optimized hyperparameters are selected using Bayesian optimization, including number of GRU neurons, initial learning rate and L2 normal form regularization. Predicted values and losses are calculated using the initial parameter values. The objective function of the Bayesian optimization is used to determine the optimized hyperparameter values. Table 4 shows the search space of the hyperparameters.
The training data of adjusting the parameters under the number of iterations are recorded, and the number of iterations is terminated to derive the final fitness. The optimization process is shown in Table 5. The Bayesian optimization algorithm quickly reaches the convergence point and the minimum value of the loss function at 27 training rounds. The application of Bayesian optimization to this model is successful. The hyperparameters of the optimization model are shown in Table 6.
The loss and RMSE curves in the training of the proposed model are shown in Fig. 10. As the number of iterations increases, the loss and RMSE both decrease significantly and stabilize. The loss and RMSE decrease rapidly in the first 250 iterations, meaning the model learns quickly from the data. As the number of iterations increases, the loss stabilizes around 0 after almost 750 training iterations. Moreover, the RMSE decreases after 1500 iterations, and gradually stabilizes at 0.04. This result indicates the model is gradually improved without overfitting during the learning, and therefore has a strong generalization and prediction ability on the data.
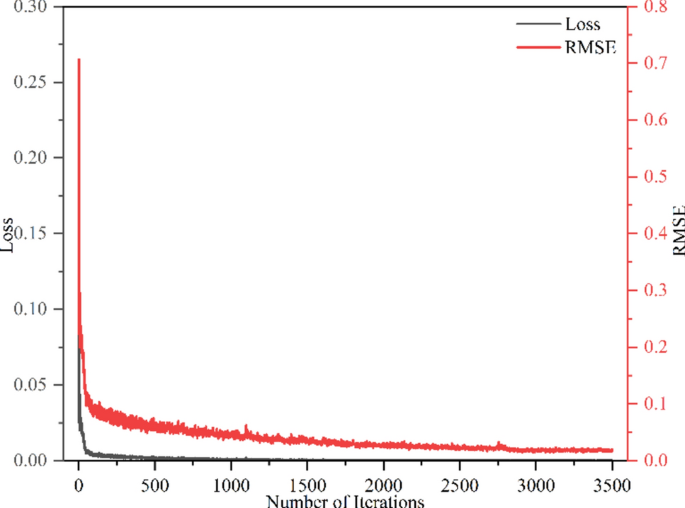
Graph of training loss.
Comparison of true and predicted values
Figure 11 shows scatter plots of the predicted values from the BO-SE-CNN-GRU model against the true values. On the scatter plots, most of the points are on or near y = x, indicating the predicted values of this model are mostly very close to the true values. This trend suggests the predictions of the model are very accurate. The point distribution shows the proposed model has the highest concentration of points on y = x for humidity prediction, followed by temperature. For humidity predictions, the highest concentration of points on y = x is predicted with a maximum relative error of 0.6%, followed by temperature (0.4%). In contrast, the prediction points for CO2 and NH3 are more scattered and slightly less effective. The maximum relative error is 4% for CO2 and 9% for NH3. The prediction performance of the model is better for temperature and humidity and slightly worse for hazardous gases. In addition, the BO-SE-CNN-GRU model predicts a better response to environmental changes and yields more accurate results.
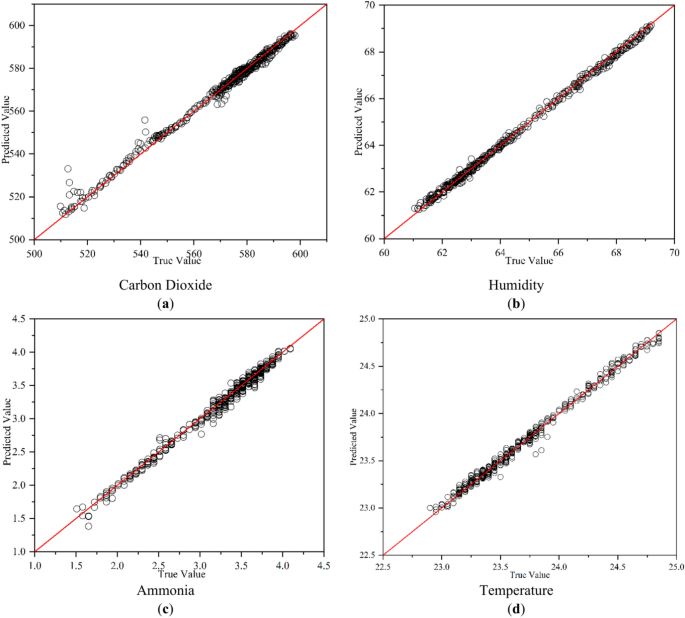
Scatter plots of model predictions. (a) carbon dioxide, (b) humidity, (c) ammonia, (d) temperature.
Comparison of model performance
Figure 12 compares the prediction errors of environmental prediction models, such as CNN-LSTM, CNN-BiLSTM, CNN-GRU, BO-CNN-GRU, and BO-SE-CNN-GRU. The overall predictions are better for both temperature and humidity. The reason is that the pig house is an enclosed environment and the indoor temperature is more stable and less variable. CO2 and NH3 concentrations in the pig house are influenced by temperature, relative humidity, and external factors such as feeding practices. Hence, the variations in CO2 and NH3 concentrations are much severer than those in temperature and humidity. Therefore, the generalizability of each model is highly expected, and the predictions for CO2 and NH3 differ significantly. The CNN-LSTM and CNN-GRU models generate poor predictions, while the CNN-BiLSTM and BO-CNN-GRU models have better overall fitting. However, when predicting NH3 during environmental mutations, the prediction accuracy of CNN-BiLSTM and BO-CNN-GRU decreases significantly and the prediction errors increase. These gases are predicted to be influenced by current conditions, but also by historical trends and patterns. The BO-SE-CNN-GRU model combines the global optimization capability of the BO, the feature recalibration capability of the SE block, the spatial feature extraction capability of the CNN, and the time-dependent learning capability of the GRU so that the model can deal more effectively with the complexity and variability of environmental data from pig farms. The architecture of the BO-SE-CNN-GRU model is suitable for capturing these non-linear relationships and patterns to derive more accurate predictions. Based on the above analyses, the BO-SE-CNN-GRU model is more accurate and predicts results closer to the actual data of the pig house environment.
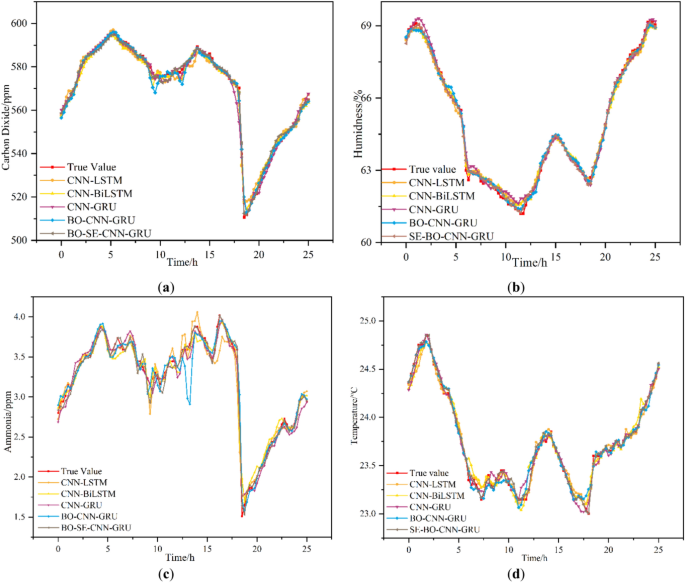
Comparison of model predictions. (a) predicted carbon dioxide, (b) predicted ammonia, (c) predicted humidity, (d) predicted temperature.
The above analyses show the BO-SE-CNN-GRU model has the best predictive effect. To accurately measure the improvement of this model over several other models, R2, MAPE, and MSE are used to compare model performances (Table 7). The R2 is between 0 and 1, and R2 closer to 1 indicates the model better fits the data. A value closer to 0 means the model fit is poorer. MAPE and MSE can quantify the amount of errors in the model predictions. The smaller MAPE and MSE suggest the prediction error of the model is smaller and the model performance is better. The comparison results show the BO-SE-CNN-GRU model has the smallest error between the predicted and actual values, the smallest MSE and MAPE, and the largest R2. The results indicate the BO-SE-CNN-GRU model can more accurately explain the variation of the actual data.
In predicting temperature and humidity, the BO-SE-CNN-GRU model has better predictions with smaller increase in MSE, MAPE, and R2 compared to other models. For example, the prediction of ammonia concentration shows a 65% reduction in MSE, a 48% reduction in MAPE, and a 3.9% improvement in R2 compared to the CNN-LSTM model. The BO-SE-CNN-GRU model can capture the non-linear relationships and complex patterns of the data, more accurately predicts the target variables, and performs better in reducing prediction errors. Therefore, it can better predict the target variable than other models. In terms of the current farming needs, the model accuracy meets the decision-making needs for environmental control of pig houses.
To further analyze the performances of these models, the dataset size can lead to large differences in the performance of the trained models, due to the different data distributions in the dataset. Therefore, without changing the original temporal order of the dataset, all-time series data of the pig house environment except the test set are equally divided into n consecutive equal parts. The 1st to the ith equal data (i = 1… n-1) are selected as the training set, and the (i + 1)th aliquot is the test set. The performance of the model on different parts of the data is evaluated, and overfitting is reduced by considering temporal correlations. To fully use the dataset and avoid too many calculations, NH3 is used for analysis and n is set to be 6.
The proposed hybrid deep learning model outperforms the remaining deep learning models in terms of R2, MSE and MAPE in six experiments (Fig. 13). The performance of the CNN-GRU model with embedded SE block outperforms the BO-CNN-GRU model (Fig. 13 and Table 7). The reason is that the embedding of SE makes the CNN more effectively extract features, compensating for the information loss defects of the pooling layer in the CNN and improving the generalization ability of the model. This hybrid deep learning model further improves the CNN-GRU deep learning model, combines the automatic optimization of Bayesian optimization algorithm and SE module to improve the extraction of feature information, and improves the prediction accuracy. Compared with different models, the BO-SE-CNN-GRU model has better performance with higher accuracy and robustness.
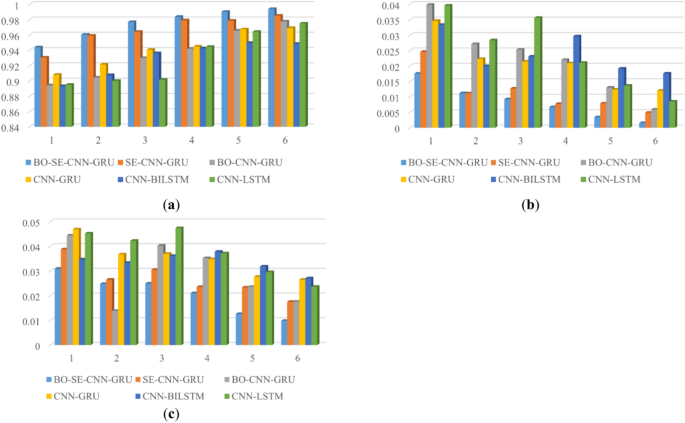
Performance comparison of models trained six times. (a) R2, (b) MSE, (c) MAPE.
Conclusions
A novel pig house environment prediction model that incorporates Bayesian optimization, squeeze and excitation block, convolutional neural network and gated recurrent unit is proposed. Bayesian optimization is applied to the model to efficiently optimize hyperparameters, which significantly improves the prediction accuracy and generalization ability of the model. The feature extraction ability of the model is enhanced by adding the SE block to the CNN, which enables the model to automatically identify and predict the most relevant environmental features and improves the prediction accuracy. The GRU network effectively captures the time-dependency of the environmental parameters and maintains the stability of the prediction, even in the face of a complex dynamic environment. The environmental prediction effectiveness of various models and methods is evaluated by comparing them. Compared with other models, the BO-SE-CNN-GRU model has higher R2, lower MSE and MAPE in predicting temperature, humidity, carbon dioxide and ammonia concentrations, indicating the model can more accurately reflect the trend of the real environment. It provides useful decision support for regulation of the pig house environment, protects pig health and improves production efficiency.
Availability of data and materials
The datasets used during the current study available from the corresponding author on reasonable request.
References
-
Liu, F. et al. Review: What have we learned about the effects of heat stress on the pig industry?. Animals 16, 100349. https://doi.org/10.1016/j.animal.2021.100349 (2022).
-
Philippe, F. X., Cabaraux, J. F. & Nicks, B. Ammonia emissions from pig houses: influencing factors and mitigation techniques. Agric. Ecosyst. Environ. 2011(141), 245–260. https://doi.org/10.1016/j.agee.2011.03.012 (2011).
-
Ma, H. et al. A review on the effect of light–thermal–humidity environment in sow houses on sow reproduction and welfare. Reprod. Domest Anim 8, 1023–1045. https://doi.org/10.1111/rda.14400 (2023).
-
Philippe, F. X. & Nicks, B. Review on greenhouse gas emissions from pig houses: Production of carbon dioxide, methane and nitrous oxide by animals and manure. Agric. Ecosyst. Environ 199, 10–25. https://doi.org/10.1016/j.agee.2014.08.015 (2015).
-
Gautam, K. R., Rong, L., Zhang, G. & Bjerg, B. S. Temperature distribution in a finisher pig building with hybrid ventilation. Biosyst Eng 200, 123–137. https://doi.org/10.1016/j.biosystemseng.2020.09.006 (2020).
-
Li, H. et al. Smart temperature and humidity control in pig house by improved three-way K-means. Agric 10, 2020. https://doi.org/10.3390/agriculture1310202 (2023).
-
Godyń, D., Nowicki, J. & Herbut, P. Effects of environmental enrichment on pig welfare—A review. Animials 9, 383. https://doi.org/10.3390/ani9060383 (2019).
-
Bhujel, A., Arulmozhi, E., Moon, B. E. & Kim, H. T. Deep-learning-based automatic monitoring of pigs’ physico-temporal activities at different greenhouse gas concentrations. Animals 11, 3089. https://doi.org/10.3390/ani11113089 (2021).
-
Taki, M., Mehdizadeh, S. A., Rohani, A., Rahnama, M. & Rahmati-Joneidabad, M. Applied machine learning in greenhouse simulation; new application and analysis. Inf. Process. Agric. 5, 253–268. https://doi.org/10.1016/j.inpa.2018.01.003 (2018).
-
Wang, Z. & Chen, Y. Data-driven modeling of building thermal dynamics: Methodology and state of the art. Energy Build. 203, 109405. https://doi.org/10.1016/j.enbuild.2019.109405 (2019).
-
Xie, Q., Ni, J., Bao, J. & Su, Z. A thermal environmental model for indoor air temperature prediction and energy consumption in pig building. Build. Environ. 161, 106238. https://doi.org/10.1016/j.buildenv.2019.106238 (2019).
-
Cooper, K., Parsons, D. J. & Demmers, T. A thermal balance model for livestock buildings for use in climate change studies. J. Agr. Eng. Res. 69, 43–52. https://doi.org/10.1006/jaer.1997.0223 (1998).
-
Zhao, Y., Xin, H., Shepherd, T. A., Hayes, M. D. & Stinn, J. P. Modelling ventilation rate, balance temperature and supple-mental heat need in alternative vs. conventional laying-hen housing systems. Biosyst. Eng. 3, 311–323. https://doi.org/10.1016/j.biosystemseng.2013.03.010 (2013).
-
Wang, Y., Zheng, W., Shi, H. & Li, B. Optimising the design of confined laying hen house insulation requirements in cold climates without using supplementary heat. Biosyst. Eng. 174, 282–294. https://doi.org/10.1016/j.biosystemseng.2018.07.011 (2018).
-
Escamilla-GarcÃa, A., Soto-Zarazúa, G. M., Toledano-Ayala, M., Rivas-Araiza, E. & Gastélum-Barrios, A. Applications of artificial neural networks in greenhouse technology and overview for smart agriculture development. Appl. Sci. 10, 3835. https://doi.org/10.3390/app10113835 (2020).
-
Liu, Z., Liu, X. & Zhao, K. Haze prediction method based on stacking learning. Stovh Env. Res. Risk A https://doi.org/10.1007/s00477-023-02619-6 (2023).
-
Alber, O. et al. Modeling and predicting mean indoor radon concentrations in Austria by generalized additive mixed models. Stovh Env. Res. Risk A 379, 3435–3449. https://doi.org/10.1007/s00477-023-02457-6 (2023).
-
Aly, M. S., Darwish, S. M. & Aly, A. A. High performance machine learning approach for reference evapotranspiration estimation. Stovh Env. Res. Risk A 38, 689–713. https://doi.org/10.1007/s00477-023-02594-y (2024).
-
Song, L. et al. Research on prediction of ammonia concentration in QPSO-RBF cattle house based on KPCA nuclear principal component analysis. Procedia Comput. Sci. 188, 103–113. https://doi.org/10.1016/j.procs.2021.05.058 (2021).
-
Fourati, F. & Chtourou, M. A greenhouse control with feed-forward and recurrent neural networks. Simul. Model Pract. Theory 15, 1016–1028. https://doi.org/10.1016/j.simpat.2007.06.001 (2007).
-
Ding, L. et al. Prediction model of ammonia emission from chicken manure based on fusion of multiple environmental parameters. Trans. Chin. Soc. Agric. Mach. 53, 366–375 (2022).
-
Butler, K. T., Davies, D. W., Cartwright, H., Isayev, O. & Walsh, A. Machine learning for molecular and materials science. Nature 559, 547–555. https://doi.org/10.1038/s41586-018-0337-2 (2018).
-
Chandra, R., Ong, Y. & Goh, C. Co-evolutionary multi-task learning for dynamic time series prediction. Appl. Soft Comput. 70, 576–589. https://doi.org/10.1016/j.asoc.2018.05.041 (2018).
-
Zhang, Y., Zhang, W., Wu, C., Zhu, F. & Li, Z. Prediction model of pigsty temperature based on ISSA-LSSVM. Agric 13, 1710. https://doi.org/10.3390/agriculture13091710 (2023).
-
Xie, Q., Ni, J. & Su, Z. A prediction model of ammonia emission from a fattening pig room based on the indoor concentration using adaptive neuro fuzzy inference system. J. Hazard Mater. 325, 301–309. https://doi.org/10.1016/j.jhazmat.2016.12.010 (2017).
-
Xie, Q., Zheng, P., Bao, J. & Su, Z. Thermal environment prediction and validation based on deep learning algorithm in closed pig house. Trans. Chin. Soc. Agric. Mach. 51, 353–361 (2020).
-
Zang, J. et al. Prediction model of carbon dioxide con-centration in pig house based on deep learning. Atmos 13, 1130. https://doi.org/10.3390/atmos13071130 (2022).
-
Peng, S. et al. Prediction of ammonia concentration in a pig house based on machine learning models and environmental parameters. Animals 13, 165. https://doi.org/10.3390/ani13010165 (2022).
-
Ji, R., Shi, S., Liu, Z. & Wu, Z. Decomposition-based multi-step forecasting model for the environmental variables of rabbit houses. Animals 13, 546. https://doi.org/10.3390/ani13030546 (2023).
-
Guo, X., Lian, J., Li, H. & Sun, K. Ammonia concentration forecasting algorithm in layer house based on two-stage attention mechanism and LSTM. J. China Agric. Univ. 26, 187–195 (2021).
-
Guo, Z. et al. Research on indoor environment prediction of pig house based on OTDBO–TCN–GRU algorithm. Animals 14, 863. https://doi.org/10.3390/ani14060863 (2024).
-
Liu, T., Qi, S., Qiao, X. & Liu, S. A hybrid short-term wind power point-interval prediction model based on combination of improved preprocessing methods and entropy weighted GRU quantile regression network. Energy 288, 129904. https://doi.org/10.1016/j.energy.2023.129904 (2024).
-
Guan, H., Yan, R., Tang, H. & Xiang, J. Intelligent fault diagnosis of hydraulic multi-way valve using the improved SECNN-GRU method with mRMR feature selection. Sens 23, 9371. https://doi.org/10.3390/s23239371 (2023).
-
Xie, Q., Ni, J. Q., Li, E., Bao, J. & Zheng, P. Sequential air pollution emission estimation using a hybrid deep learning model and health-related ventilation control in a pig building. J. Clean Prod. 371, 133714. https://doi.org/10.1016/j.jclepro.2022.133714 (2022).
-
Kim, J.-Y. & Oh, J.-S. Electric consumption forecast for ships using multivariate bayesian optimization-SE-CNN-LSTM. J. Mar. Sci. Eng. 11, 292. https://doi.org/10.3390/jmse11020292 (2023).
-
Wang, H., Xu, J., Yan, R. & Gao, R. X. A new intelligent bearing fault diagnosis method using SDP representation and SE-CNN. IEEE T Instrum. Meas. 5, 2377–2389. https://doi.org/10.1109/TIM.2019.2956332 (2020).
-
Gao, Y. et al. Recognition of aggressive behavior of group-housed pigs based on CNN-GRU hybrid model with spatio-temporal attention mechanism. Comput. Electron Agr. 205, 107606. https://doi.org/10.1016/j.compag.2022.107606 (2023).
-
Wang, J. et al. A deep learning framework combining CNN and GRU for im-proving wheat yield estimates using time series remotely sensed multi-variables. Comput. Electron Agr. 206, 107705. https://doi.org/10.1016/j.compag.2023.107705 (2023).
-
Thiede, L. A. & Parlitz, U. Gradient based hyperparameter optimization in echo state networks. Neural Netw. 115, 23–29. https://doi.org/10.1016/j.neunet.2019.02.001 (2019).
-
Stochino, F. & Lopez Gayarre, F. L. Reinforced concrete slab optimization with simulated annealing. Appl. Sci 9, 3161. https://doi.org/10.3390/app9153161 (2019).
-
Wu, T. et al. A capacity configuration control strategy to alleviate power fluctuation of hybrid energy storage system based on improved particle swarm optimization. Energies 12, 642. https://doi.org/10.3390/en12040642 (2019).
-
Islam, A. M. et al. An attention-guided deep-learning-based network with bayesian optimization for forest fire classification and localization. Forests 14, 2080. https://doi.org/10.3390/f14102080 (2023).
Acknowledgements
This research is funded by Collaborative Innovation Achievement Project of “Double First-class” Disciplines in Heilongjiang Province, grant number LJGXCG2024-P25, Key Projects of Qiqihar City Scientific and Technological Plan, grant number ZDGG-202202, the Basic Research Fund for State-owned Universities in Heilongjiang Province, grant number 145409605, General Research Project on Higher Education Teaching Reform in Heilongjiang Province, grant number SJGY20220410, and Educational Science Research Project of Qiqihar University, grant number GJQTYB202212.
Author information
Authors and Affiliations
Contributions
Conceptualization, Z.W. and K.X.; methodology, K.X.; software, K.X.; validation, K.X., and Y.L.; formal analysis, K.X.; investigation, Y.C.; resources, Z.W. and W.S.; data curation, W.S., and K.X.; writing—original draft preparation, K.X.; writing—review and editing, Z.W.; visualization, K.X., and Y.C.; supervision, Z.W., and Y.C.; project administration, Z.W.; funding acquisition, Z.W. and W.S. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wu, Z., Xu, K., Chen, Y. et al. A new prediction model based on deep learning for pig house environment.
Sci Rep 14, 31141 (2024). https://doi.org/10.1038/s41598-024-82492-7
-
Received: 17 August 2024
-
Accepted: 05 December 2024
-
Published: 28 December 2024
-
DOI: https://doi.org/10.1038/s41598-024-82492-7
Keywords
Search
RECENT PRESS RELEASES

{kind=link}