Accelerating on-device ML on Meta’s family of apps with ExecuTorch
July 28, 2025
- ExecuTorch is the PyTorch inference framework for edge devices developed by Meta with support from industry leaders like Arm, Apple, and Qualcomm.
- Running machine learning (ML) models on-device is increasingly important for Meta’s family of apps (FoA). These on-device models improve latency, maintain user privacy by keeping data on users’ devices, and enable offline functionality.
- We’re showcasing some of the on-device AI features, powered by ExecuTorch, that are serving billions of people on Instagram, WhatsApp, Messenger, and Facebook.
- These rollouts have significantly improved the performance and efficiency of on-device ML models in Meta’s FoA and eased the research to production path.
Over the past year, we’ve rolled out ExecuTorch, an open-source solution for on-device inference on mobile and edge devices, across our family of apps (FoA) and seen significant improvements in model performance, privacy enhancement, and latency over our previous on-device machine learning (ML) stack.
ExecuTorch was built in collaboration with industry leaders and uses PyTorch 2.x technologies to convert models into a stable and compact representation for efficient on-device deployment. Its compact runtime, modularity, and extensibility make it easy for developers to choose and customize components – ensuring portability across platforms, compatibility with PyTorch, and high performance.
Adopting ExecuTorch has helped us enhance our user experiences in our products and services used by billions of people all over the world.
The following are just a few examples of the various ML models on our apps on Android and iOS devices that ExecuTorch supports.
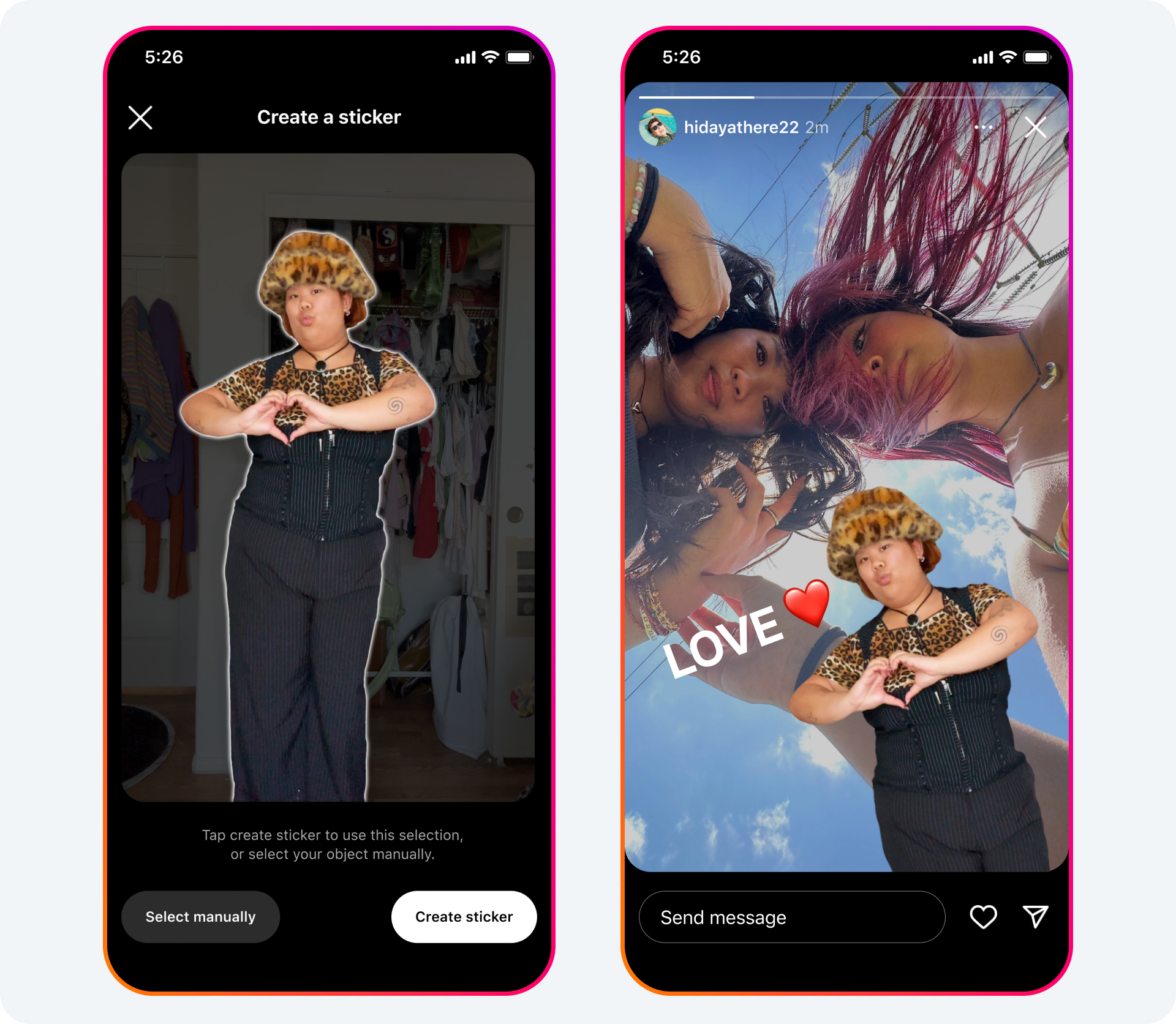
Enabling Cutouts on Instagram
Cutouts is one of Instagram’s latest features for creative expression and storytelling. It lets people transform photos and videos of their favorite moments into animated, personalized stickers that they can share via Reels or Stories. We migrated the Cutouts feature in Instagram to run with ExecuTorch by enabling SqueezeSAM, a lightweight version of the Meta Segment Anything Model (SAM). For both Android and iOS, ExecuTorch was significantly faster compared to the older stack, translating into increases in Cutouts’ daily active users (DAU).
Improving video and call quality on WhatsApp
WhatsApp needs to be usable and reliable regardless of your network connection bandwidth. To achieve this, we developed bandwidth estimation models, tailored for various platforms. These models help detect and utilize available network bandwidth, optimizing video streaming quality without compromising the smoothness of video calls.
These models need to be highly accurate and run as efficiently as possible. By leveraging ExecuTorch, we have observed improvements for the bandwidth estimation models in performance, reliability, and efficiency metrics. Specifically, we reduced the model load time and average inference time substantially while reducing app not responsive (ANR) metrics. Along the way, we further strengthened security guarantees compared to the older PyTorch mobile framework by adding fuzzing tests, which involve supplying invalid or random inputs to a program and monitoring for exceptions. With the positive signal from these releases, we are now migrating several other key WhatsApp models, such as ones for on-device noise-canceling and video enhancement, to ExecuTorch as well.

Shipping on-device ML for end-to-end encryption on Messenger
End-to-end encryption (E2EE) on Messenger ensures that no one except you and the people you’re talking to can see your messages, not even Meta. ExecuTorch has enabled E2EE on Messenger by moving server side models to run on-device, allowing data transfers to remain encrypted.
To enable E2EE, we migrated and deployed several models, including an on-device language identification (LID) model on Messenger. LID is a Messenger model that detects the language of given text and enables various downstream tasks, including translation, message summarization, and personalized content recommendations. With ExecuTorch, on-device LID is significantly faster and conserves server and network capacity.
To preserve Messenger’s E2EE environment, we have also leveraged ExecuTorch to move other Messenger models on-device, including one for optimizing video calling quality (similar to WhatsApp’s bandwidth estimation models) and another for image cutouts (similar to Cutouts on Instagram). These shifts resulted in improved infrastructure efficiency by freeing up capacity and enabling us to scale these features globally.
Background music recommendations for Facebook
Facebook employs a core AI model called SceneX that performs a variety of tasks, including image recognition/categorization, captioning, creating AI-generated backgrounds for images, and image safety checks. Shifting SceneX to ExecuTorch now allows it to enhance people’s Facebook Stories by suggesting background music based on images.
With the ExecuTorch rollout, we saw performance improvements in SceneX across the board from low- to high-end devices compared to the older stack. Several other models, including which enhance image quality and perform background noise reduction during calls, are now in various stages of A/B testing.
Building the future of on-device AI with the ExecuTorch Community
We hope the results we’ve seen leveraging ExecuTorch to help solve some of Meta’s on-device ML challenges at scale will be encouraging to the rest of the industry. We invite you to contribute to ExecuTorch and share feedback on our GitHub page. You can also join our growing community on the ExecuTorch Discord server.
We look forward to driving more innovation in on-device ML and shaping the future of on-device AI together with the community.
Search
RECENT PRESS RELEASES
Related Post




{kind=link}
{kind=link}
{kind=link}
{kind=link}