Indexing code at scale with Glean
December 19, 2024
- We’re sharing details about Glean, Meta’s open source system for collecting, deriving, and working with facts about source code.
- In this blog post we’ll talk about why a system like Glean is important, explain the rationale for Glean’s design, and run through some of the ways we’re using Glean to supercharge our developer tooling at Meta.
In August 2021 we open-sourced our code indexing system Glean. Glean collects information about source code and provides it to developer tools through an efficient and flexible query language. We use Glean widely within Meta to power a range of developer tools including code browsing, code search, and documentation generation.
Code Indexing
Many tools that developers use rely on information extracted from the code they’re working on. For example:
- Code navigation (“Go to definition”) in an IDE or a code browser;
- Code search;
- Automatically-generated documentation;
- Code analysis tools, such as dead code detection or linting.
The job of collecting information from code is often called code indexing. A code indexing system’s job is to efficiently answer the questions your tools need to ask, such as, “Where is the definition of MyClass?” or “Which functions are defined in myfile.cpp?”
An IDE will typically do indexing as needed, when you load a new file or project for example. But the larger your codebase, the more important it becomes to do code indexing ahead of time. For large projects it becomes impractical to have the IDE process all the code of your project at startup and, depending on what language you’re using, that point may come earlier or later: C++ in particular is problematic due to the long compile times.
Moreover, with a larger codebase and many developers working on it, it makes sense to have a shared centralized indexing system so that we don’t repeat the work of indexing on every developer’s machine. And as the data produced by indexing can become large, we want to make it available over the network through a query interface rather than having to download it.
This leads to an architecture like this:
In practice the real architecture is highly distributed:
- Indexing can be heavily parallelized and we may have many indexing jobs running concurrently;
- The query service will be widely distributed to support load from many clients that are also distributed;
- The databases will be replicated across the query service machines and also backed up centrally.
We’ve found that having a centralized indexing infrastructure enables a wide range of powerful developer tools. We’ll talk about some of the ways we’ve deployed Glean shortly, but first we’ll dive into the rationale for Glean’s design.
How is Glean different?
Code indexing systems have been around for a while. For example, there’s a well-established format called LSIF used by IDEs that caches information about code navigation.
When we designed Glean we wanted a system that wasn’t tied either to particular programming languages or to any particular use case. While we had some use cases in mind that we wanted to support—primarily code navigation of course—we didn’t want to design the system around one use case, in the hope that a more general system would support emerging requirements further into the future.
Therefore:
- Glean doesn’t decide for you what data you can store. Indeed, most languages that Glean indexes have their own data schema and Glean can store arbitrary non-programming-language data too. The data is ultimately stored using RocksDB, providing good scalability and efficient retrieval.
- Glean’s query language is very general. It’s a declarative logic-based query language that we call Angle (“Angle” is an anagram of “Glean”, and means “to fish”). Angle supports deriving information automatically, either on-the-fly at query time or ahead of time; this is a powerful mechanism that enables Glean to abstract over language-specific data and provide a language-neutral view of the data.
Storing arbitrary language-specific data can be very powerful. For example, in C++ we use the detailed data to detect dead code such as unused #include or using statements. The latter in particular is rather tricky to do correctly and requires the data to include some C++-specific details, such as which using statement is used to resolve each symbol reference.
On the other hand, clients often don’t want the full language-specific data. They want to work at a higher level of abstraction. Imagine asking questions like, “Give me the names and locations of all the declarations in this file”, which should work for any language, and which you could use to implement a code outline feature in a code browser. Glean can provide this language-neutral view of the data by defining an abstraction layer in the schema itself – the mechanism is similar to SQL views if you’re familiar with those. This means that we don’t have to compromise between having detailed language-specific data or a lowest-common-denominator language-neutral view; we can have both.
This generality has allowed Glean to extend to a number of use cases beyond what we originally envisaged. We’ll cover some of those later in this post.
A taste of Angle
Glean has a unified language, Angle, for specifying both schemas and queries. As mentioned above, each language that we index has its own schema. To give you a flavor of this, here’s a fragment of the schema for C++ function declarations:
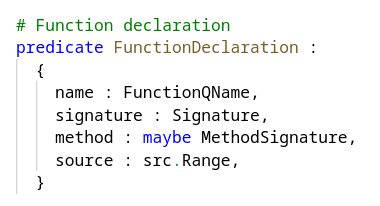
Defining a schema for Glean is just like writing a set of type definitions. The braces surround a record definition, with a set of fields and their types.
- A FunctionDeclaration is a predicate (roughly equivalent to a table in SQL).
- The instances of a predicate are called facts (roughly equivalent to rows in SQL).
- A predicate is a thing that you can query, and a query returns facts.
To query efficiently you specify a prefix of the fields. So, for example, we can retrieve a particular FunctionDeclaration efficiently if we know its name.
Let’s write a query to find the function folly::parseJson:

Without going into all the details, at a high level this query specifies that we want to find FunctionDeclaration facts that have a particular name and namespace. Glean can return results for this query in about a millisecond.
Angle supports more complex queries too. For example, to find all classes that inherit from a class called exception and have a method called what that overrides a method in a base class:

This query returns the first results in a few milliseconds, and because there might be a lot of results we can fetch the results incrementally from the query server.
Incremental indexing
An important innovation in Glean is the ability to index incrementally. As the codebase grows, and the rate of change of the codebase increases (a monorepo suffers from both of these problems) we find that we can’t provide up-to-date information about the latest code because indexing the entire repository can take a long time. The index is perpetually out of date, perhaps by many hours.
The solution to this scaling problem is to process just the changes. In terms of computer science big-O notation, we want the cost of indexing to be O(changes) rather than O(repository).
But actually achieving this is not as straightforward as it might sound.
We don’t want to destructively modify the original data, because we would like to be able to provide data at multiple revisions of the repository, and to do that without storing multiple full-sized copies of the data. So we would like to store the changes in such a way that we can view the whole index at both revisions simultaneously.
Even if we figure out a way to represent the changes, in practice it isn’t possible to achieve O(changes) for many programming languages. For example, in C++ if a header file is modified, we have to reprocess every source file that depends on it (directly or indirectly). We call this the fanout. So in practice the best we can do is O(fanout).
Glean solves the first problem with an ingenious method of stacking immutable databases on top of each other. A stack of databases behaves just like a single database from the client’s perspective, but each layer in the stack can non-destructively add information to, or hide information from, the layers below.
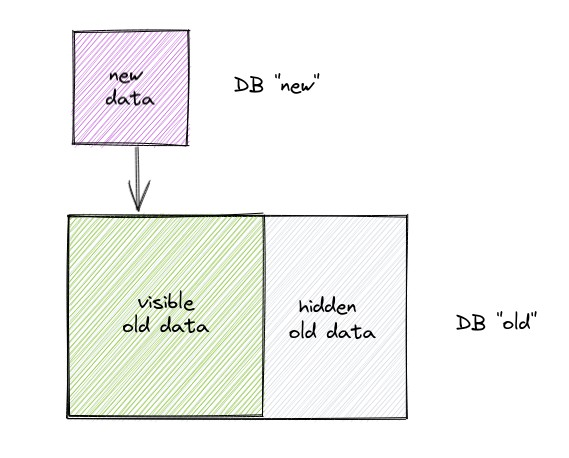
The full details are beyond the scope of this post, for more on how incrementality works see: Incremental indexing with Glean.
Finding the fanout of a set of changes is different for each language. Interestingly the fanout can often be obtained using Glean queries: for example for C++, the fanout is calculated by finding all the files that #include one of the changed files, and then repeating that query until there are no more files to find.
How we use Glean at Meta
Code navigation
Code navigation at scale, on large monorepos containing millions of lines in diverse programming languages, is a challenging problem. But what makes it different from the code navigation support available in modern IDEs, other than scale? In our experience, code indexing a la Glean offers the following advantages over IDEs:
- Instantly available: Just open the code browser web app (our internal tool uses Monaco) and navigate without waiting for the IDE, build system, and LSP server to initialize
- More widely available: You can integrate code navigation in pretty much any app that shows code! One particularly useful integration is in your code review tool (ours is called Phabricator), but more on that later.
- Full repo visibility: Glean allows you to, for example, find all the references to a function, not just the ones visible to the IDE. This is particularly useful for finding dead code, or finding clients of an API that you want to change.
- Symbol search for all the languages across the whole repository.
- Cross language navigation: A common situation that comes up is a remote procedure call (RPC). When browsing the code you might want to jump to the service definition or, indeed, to the service implementation itself. Another case is languages with a foreign function interface (FFI), where you would like to browse from an FFI call to the corresponding definition in the target language.
Our architecture for code navigation is based on Glass, a symbol server that abstracts all the complexities of Glean by implementing the usual code navigation logic in a simple but powerful API. The code browser needs only a single Glass API call, documentSymbols(repo,path,revision), to obtain a list of all the definitions and references in a source file, including source and target spans. The list of definitions is used to render an outline of the file, and the list of references to render underlines that can be hovered over or clicked to navigate. Finally, other code browser features like Find References or Call Hierarchy are also driven by API calls to Glass.
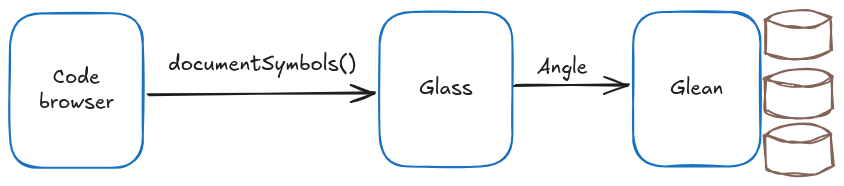
The code for Glass is also open-source, you can find it in glean/glass on GitHub.
Speeding up the IDE
Using an IDE such as VS Code on a large project, or a project with a large set of dependencies, or in a large monorepo tends to lead to a degraded experience as the IDE isn’t able to analyze all the code that you might want to explore. At Meta we’re using Glean to plug this gap for C++ developers: Because Glean has already analyzed the whole repository, C++ developers have access to basic functionality such as go-to-definition, find-references, and doc comment hovercards for the whole repository immediately on startup. As the IDE loads the files the developer is working on, the C++ language service seamlessly blends the Glean-provided data with that provided by the native clangd backend.
Our target was C++ developers initially because that group typically has the worst IDE experience due to the long compile times, but the approach is not specific to C++ and we imagine other languages following the same path in the future.
Documentation generation
The data we store in Glean includes enough information to reconstruct the full details of an API: classes, methods, type signatures, inheritance, and so on. Glean also collects documentation from the source code when it uses the standard convention for the language, e.g., in C++ the convention is /// comment or /** comment */. With API data and documentation strings in Glean we can produce automatically-generated documentation on demand.
Here’s an example page for the folly::Singleton type:
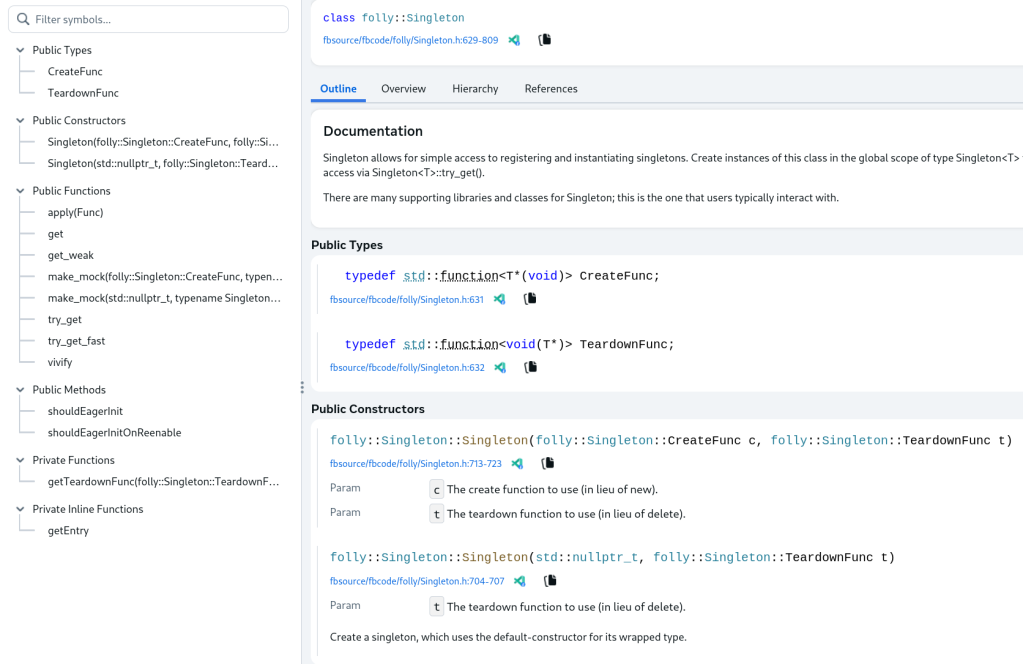
The data for these pages is produced by Glass and rendered by a client-side UI. The documentation is fully hyperlinked so the user can navigate around all the APIs throughout the repository easily. Meta engineers get consistent code documentation integrations across all the programming languages supported by Glean.
Symbol IDs
Glass assigns every symbol a symbol ID, a unique string that identifies the symbol. For example, the symbol ID for folly::Singleton would be something like, REPOSITORY/cpp/folly/Singleton. The symbol ID can be used to link directly to the documentation page for the symbol, so there’s a URL for every symbol that doesn’t change even if the symbol’s definition moves around.
We can use the symbol ID to request information about a symbol from Glass, for example to find all the references to the symbol throughout the repository. All of this works for every language, although the exact format for a symbol ID varies per language.
Analyzing code changes
Glean indexing runs on diffs (think, “pull requests”) to extract a mechanical summary of the changeset that we call a diff sketch. For example, a diff might introduce a new class, remove a method, add a field to a type, introduce a new call to a function, and so on. The diff sketch lists all of these changes in a machine-readable form.
Diff sketches are used to drive a simple static analysis that can identify potential issues that might require further review. They can also be used to drive non-trivial lint rules, rich notifications, and semantic search over commits. One example of the latter is connecting a production stack trace to recent commits that modified the affected function(s), to help root-cause performance issues or new failures.
Indexing diffs also powers code navigation in our code review tools, giving code reviewers access to accurate go-to-definition on the code changes being reviewed, along with other code insights such as type-on-hover and documentation. This is a powerful lift to the code review process, making it easier for reviewers to understand the changes and provide valuable review feedback. At Meta this is enabled for a variety of different languages, including C++, Python, PHP, Javascript, Rust, Erlang, Thrift, and even Haskell.
More applications for Glean
Aside from the primary applications described above, Glean is also used to
- Analyse build dependency graphs.
- Detect and remove dead code.
- Track the progress of API migrations.
- Measure various metrics that contribute to code complexity.
- Track test coverage and select tests to run.
- Automate data removal.
- Retrieval Augmented Generation (RAG) in AI coding assistants
Furthermore, there are an ever-growing number of ad-hoc queries made by various people and systems to solve a variety of problems. Having a system like Glean means you can ask questions about your code: we don’t know all the questions we might want to ask, nor do we know all the data we might want to store, so Glean deliberately aims to be as general as possible on both of these fronts.
Try Glean today
Visit the Glean site for more details, technical documentation, and information on how to get started.
Search
RECENT PRESS RELEASES
Related Post


{kind=link}
{kind=link}