Meta Platforms transforms audio editing with prompt-based sound separation
December 16, 2025
Meta Platforms Inc. is bringing prompt-based editing to the world of sound with a new model called SAM Audio that can segment individual sounds from complex audio recordings.
The new model, available today through Meta’s Segment Anything Playground, has the potential to transform audio editing into a streamlined process that’s far more fluid than the cumbersome tools used today to achieve the same goal. Just as the company’s earlier Segment Anything models dramatically simplified video and image editing with prompts, SAM Audio is doing the same for sound editing.
The company said in a blog post that SAM Audio has incredible potential for tasks such as music creation, podcasting, television, film, scientific research, accessibility and just about any other use case that involves sound.
For instance, it makes it possible to take a recording of a band and isolate the vocals or the guitar with a single, natural language prompt. Alternatively, someone recording a podcast in a city might want to filter out the noise of the traffic – they can either turn down the volume of the passing cars or eliminate their sound entirely. The model could also be used to delete that inopportune moment when a dog starts barking in an otherwise perfect video presentation someone has just recorded.
SAM Audio is the latest addition to Meta’s Segment Anything model collection. Its earlier models, such as SAM 3 and SAM 3D, were all focused on using prompts to manipulate images, but until now the task of editing sound has always been much more complex. Typically, content creators have had no choice but to work with various clunky and difficult-to-use tools that can often only be applied to single-purpose use cases, Meta explained. As a unified model, SAM Audio is able to identity and edit out any kind of sound.
The core innovation in SAM Audio is the Perception Encoder Audiovisual engine, which is built on Meta’s open-source Perception Founder model that was released earlier this year. PE-AV can be thought of as SAM Audio’s “ears,” Meta explained, allowing it to comprehend the sound the user has described in the prompt, isolate it in the audio file, and then slice it out without affecting any of the other sounds.
SAM Audio is a multimodal model that’s able to support three kinds of prompts. The most standard way people will use it is through text prompting – for instance, someone might type “dog barking” or “singing voice” to identify a specific sound within their audio track.
It also supports visual prompting, so when a user is editing the audio in a video, they can click on the person or object that’s generating sound to have the model isolate or remove it, without having to go through the trouble of typing it. That could be useful in those situations where the user struggles to articulate the exact nature of the sound in question.
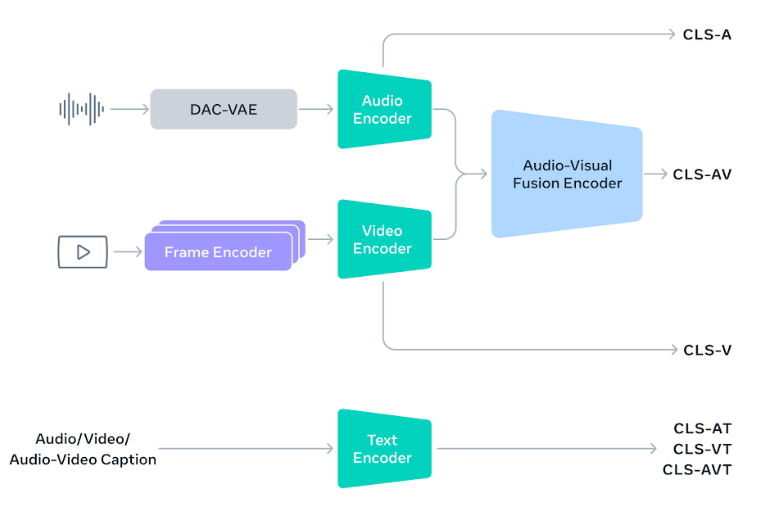
Finally, the model also supports “span prompting,” which is an entirely new kind of mode that allows users to mark the time segment where a certain sound first occurs. Meta said the three prompts can be used individually or in any combination, meaning users will have extremely precise control over how they isolate and separate different sounds. “We see so many potential use cases, including sound isolation, noise filtering, and more to help people bring their creative visions to life, and we’re already using SAM Audio to help build more creative tools in our apps,” Meta wrote in a blog post.
How does it sound?
Although SAM Audio isn’t the first AI model focused on sound editing, the audio separation discipline is nascent. But it’s something Meta hopes to grow, and to encourage further innovation in this are,a it has created a new benchmark for models of this type, called SAM Audio-Bench.
The benchmark covers all major audio domains, including speech, music and general sound effects, together with text, visual and span-prompt types, Meta said. The purpose is to fairly assess all audio separation models and provide developers with a way to accurately measure how effective they are. Going by the results, Meta said SAM Audio represents a significant advance in audio separation AI, outperforming its competitors on a wide range of tasks:
“Performance evaluations show that SAM Audio achieves state-of-the-art results in modality-specific tasks, with mixed-modality prompting (such as combining text and span inputs) delivering even stronger outcomes than single-modality approaches. Notably, the model operates faster than real-time (RTF ≈ 0.7), processing audio efficiently at scale from 500M to 3B parameters.”
Meta’s claims that SAM Audio is the best model in its class aren’t really a surprise, but the company did admit some limitations. For instance, it does not support audio-based prompts, which seems like a necessary capability for such models, and it also cannot perform complete audio separation without any prompting. It also struggles with “similar audio events,” such as isolating an individual voice from a choir or an instrument from an orchestra, meaning there’s still lots of room for improvement.
SAM Audio is available to try out now in Segment Anything Playground, along with all of the company’s earlier Segment Anything models for image and video editing.
Meta said it’s hoping to have a real-world impact with SAM Audio, particularly in terms of accessibility. To that end, it’s working with the hearing-aid manufacturer Starkey Laboratories Inc. to explore how SAM Audio can be used to enhance the capabilities of its devices for people who are hard of hearing. It’s also partnering with 2gether-International, a startup accelerator for disabled founders, to explore other ways SAM Audio might be used.
Images: Meta
Support our mission to keep content open and free by engaging with theCUBE community. Join theCUBE’s Alumni Trust Network, where technology leaders connect, share intelligence and create opportunities.
- 15M+ viewers of theCUBE videos, powering conversations across AI, cloud, cybersecurity and more
- 11.4k+ theCUBE alumni — Connect with more than 11,400 tech and business leaders shaping the future through a unique trusted-based network.
About SiliconANGLE Media
SiliconANGLE Media is a recognized leader in digital media innovation, uniting breakthrough technology, strategic insights and real-time audience engagement. As the parent company of SiliconANGLE, theCUBE Network, theCUBE Research, CUBE365, theCUBE AI and theCUBE SuperStudios — with flagship locations in Silicon Valley and the New York Stock Exchange — SiliconANGLE Media operates at the intersection of media, technology and AI.
Founded by tech visionaries John Furrier and Dave Vellante, SiliconANGLE Media has built a dynamic ecosystem of industry-leading digital media brands that reach 15+ million elite tech professionals. Our new proprietary theCUBE AI Video Cloud is breaking ground in audience interaction, leveraging theCUBEai.com neural network to help technology companies make data-driven decisions and stay at the forefront of industry conversations.
Search
RECENT PRESS RELEASES
Related Post


{kind=link}
{kind=link}