Meta’s new VL-JEPA model shifts from generating tokens to predicting concepts
January 4, 2026
Meta’s VL-JEPA outperforms massive vision-language models on world modeling tasks by learning to predict “thought vectors” instead of text tokens.

Researchers at Meta have introduced VL-JEPA, a vision-language model built on a Joint Embedding Predictive Architecture (JEPA). Unlike traditional models that focus on generating text word-by-word, VL-JEPA focuses on predicting abstract representations of the world.
This approach makes the model significantly more efficient and capable; it achieves stronger performance than standard vision-language models (VLMs) while using only 50% of the trainable parameters. Beyond its efficiency, the model supports a wide range of applications without requiring architectural modifications. VL-JEPA represents a fundamental shift in model design, moving beyond simple token prediction to a system capable of understanding representations and modeling the physical world.
The shortcomings of classic VLMs
To understand why this architecture matters, it is necessary to look at the limitations of current systems. Advanced AI requires the ability to understand, reason, and act within the physical world to assist humans. Current approaches typically rely on large vision language models (VLMs) that generate tokens. These models take visual inputs and textual queries and generate a textual response autoregressively, one token at a time.
While this method is straightforward, it is flawed for real-world tasks. First, developing these VLMs is computationally expensive because they are trained to capture both task-relevant semantics and surface-level linguistic features, such as word choice and phrasing. During training, the model wastes computing effort producing diverse token sequences that do not necessarily impact the correctness of the answer.
Second, real-time tasks like live action tracking require sparse updates (i.e., you only need an output when something changes). However, autoregressive models must complete a full decoding process before revealing the underlying meaning, introducing unnecessary latency that hampers real-time performance.
How VL-JEPA works
To appreciate VL-JEPA, it helps to understand the underlying JEPA framework. The JEPA architecture operates on a principle of prediction in “latent space.” Unlike generative models that try to reconstruct missing pixels or generate specific words (raw data), a JEPA model learns by predicting the abstract representation of a target input from the representation of a context input. By optimizing for prediction error in this abstract embedding space, the model forces itself to learn high-level semantic concepts while ignoring unpredictable surface-level noise. JEPA was first introduced by Yann LeCun (who is also a coauthor of this new paper), and has been adapted in different formats, including image (I-JEPA) and video (V-JEPA).
VL-JEPA applies this philosophy to vision and language, turning the expensive learning of data-space token generation into efficient latent-space semantic prediction.
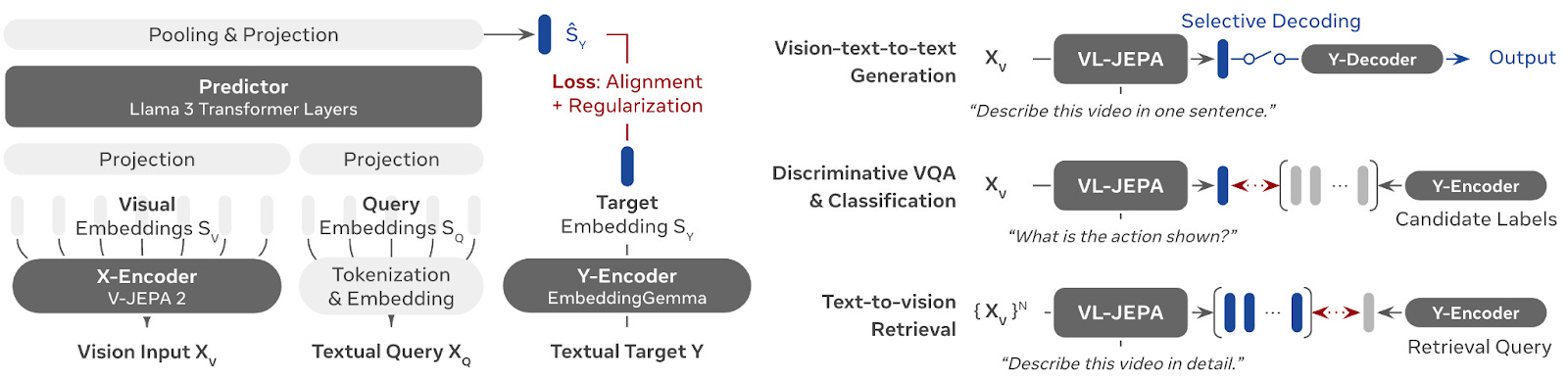
The architecture begins with an “X-Encoder” and a “Y-Encoder.” The X-Encoder, which uses the V-JEPA 2 model, compresses high-volume visual inputs (like video frames) into compact embeddings. Simultaneously, the textual query is tokenized and embedded and concatenated with the visual embedding to provide context on the task.
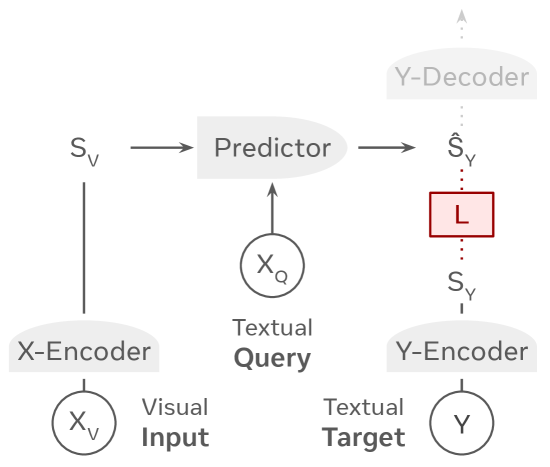
The core of the system is the “Predictor,” initialized using transformer layers from Llama 3. This component takes the visual embeddings and the query, then predicts the embedding of the target answer. Note that it does not try to predict the first word of the answer. Instead, it predicts the entire semantic concept of the answer in one go.
During the training phase, this predicted embedding is compared to the actual target embedding produced by the Y-Encoder (initialized by EmbeddingGemma), and the model optimizes itself to reduce the distance between them. For applications requiring human-readable output, such as visual question answering (VQA), a separate decoder translates the predicted embedding into text.
This shift to embedding prediction offers important advantages. Because the model is non-generative during its primary training, it is not forced to reconstruct every surface detail of the answer in token space. In a standard VLM, two valid answers like “the lamp is turned off” and “the room will go dark” might look completely different in token space. In VL-JEPA’s embedding space, however, these diverse targets map to nearby points that share similar semantics. This simplifies the learning process and eliminates the need for a heavy decoder during training.
Furthermore, because it is non-autoregressive, VL-JEPA can produce a continuous stream of “thought vectors” over a sliding window of observations. This makes it particularly efficient for online applications like live scene recognition or planning, where the system monitors the semantic stream and only triggers the text decoder when necessary.
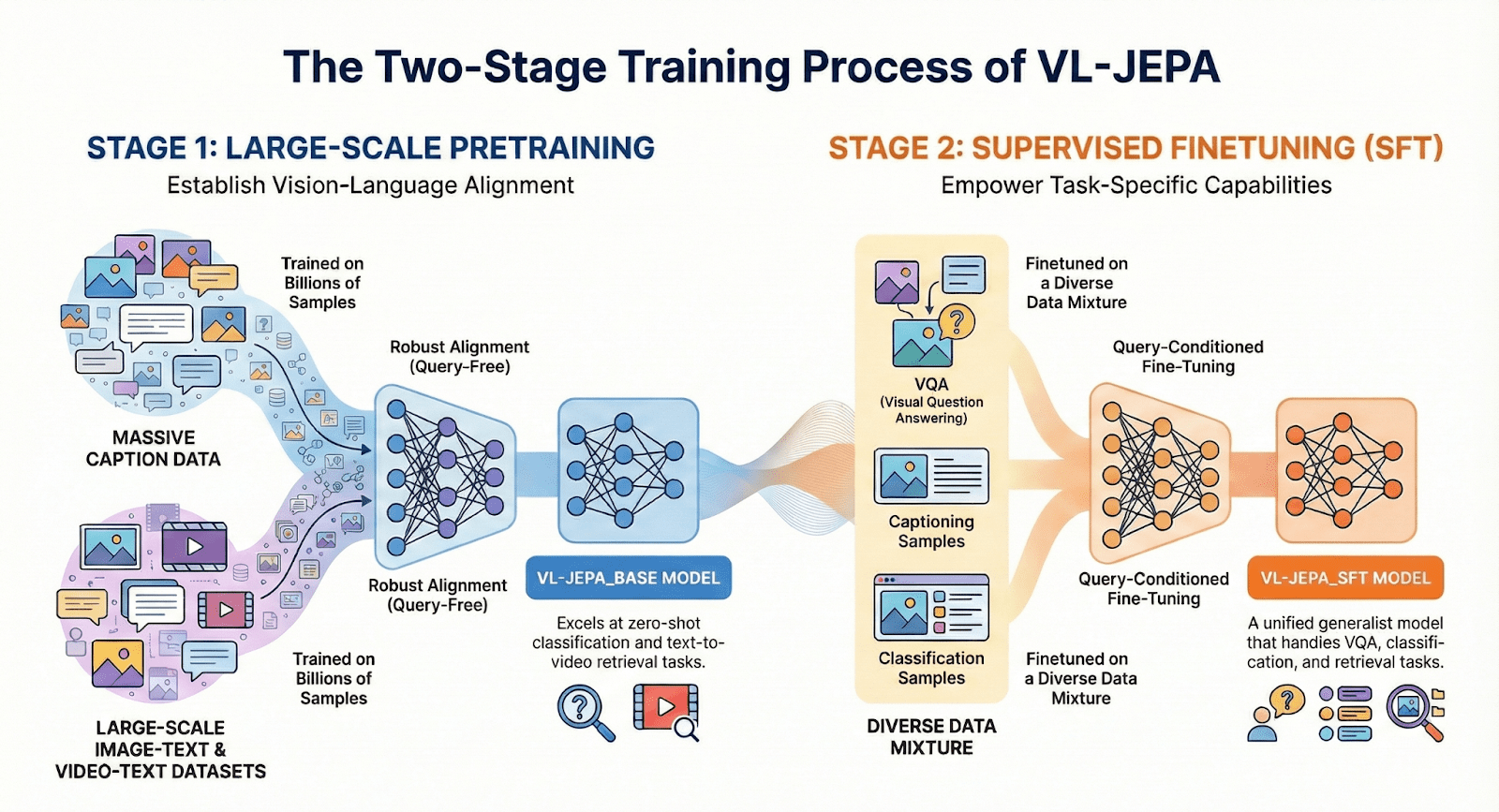
The model is trained in two distinct stages. The first is a query-free pretraining stage designed to establish robust vision-language alignment. Using massive datasets of image-text and video-text pairs, the model learns to associate visuals with language without focusing on specific tasks. This produces the VL-JEPA_BASE model, which excels at “zero-shot” tasks like classifying videos or retrieving footage based on descriptions.
The second stage is supervised fine-tuning (SFT). Here, the model switches to “query-conditioned” learning, where it is trained on a mixture of VQA, captioning, and classification samples (along with a portion of pretraining data to prevent catastrophic forgetting). The resulting VL-JEPA_SFT is a “unified generalist” capable of answering specific questions, counting objects, and reasoning about visual scenes.
VL-JEPA in action
Meta researchers validated the model’s capabilities across a broad suite of benchmarks, including eight video classification datasets and eight video retrieval datasets. They compared VL-JEPA against generalist foundation models like CLIP, SigLIP2, and Perception Encoder, as well as specialist models optimized for individual benchmarks.
In strict zero-shot settings, VL-JEPA_BASE achieved higher average accuracy (46.4% vs. 44.6%) across the classification datasets and higher average recall (58.4% vs. 58.1%) on retrieval tasks compared to the best baseline, Perception Encoder. The model proved particularly strong on motion-centric benchmarks, though it was slightly weaker on appearance-centric tasks due to having seen fewer image-text pairs than its competitors during training. However, after the supervised fine-tuning stage, VL-JEPA_SFT significantly improved, delivering performance that approached specialist models optimized for specific datasets.
In visual question answering, VL-JEPA_SFT achieved performance comparable to established VLMs like InstructBLIP and Qwen-VL, despite having only 1.6 billion parameters compared to the 7 billion or 13 billion parameters found in rival models. Perhaps most impressively, in “world modeling” tasks (where a model must identify the action that links an initial state to a final state), VL-JEPA set a new state-of-the-art accuracy of 65.7%. This score outperformed massive frontier models, including GPT-4o (53.3%), Gemini-2.0 (55.6%), and Qwen2.5-VL-72B.
For real-time applications, the model’s selective decoding mechanism demonstrated clear superiority over traditional methods. In streaming video tasks, VL-JEPA matched the output quality (measured by CIDEr score) of a uniform baseline while requiring approximately 2.85 times fewer decoding operations. This validates the premise that predicting semantic embeddings allows for more intelligent, efficient monitoring of the visual world.
While JEPA-based models are not designed for generative tasks, a large part of applications only require AI systems to understand the world and take proper actions. For these categories of applications, JEPA promises to be more flexible, accurate, and efficient than generative models.
Search
RECENT PRESS RELEASES


{kind=link}
{kind=link}